* 본 글은 학부생의 입장에서 공부 내용을 정리하기 위해 작성되었습니다. 틀린 내용이 있으면 피드백 부탁드리며, 무분별한 비방 작성시 차단 될 수 있음을 알려드립니다.
안녕하세요 파일입니다. 오늘은 컴퓨터에서 함수 호출 시 사용하는 개념인 스택 프레임(Stack Frame)에 대해 알아보겠습니다. 또한 스택 프레임 자체가 컴퓨터가 함수를 다루는 일종의 근간적 방법(?) 이므로 CPU에게 직접 명령을 내릴 수 있는 언어인 어셈블리어를 통하여 스택 프레임을 다루는 것을 보여드릴 겁니다.
물론 어셈블리어를 모르고 스택 프레임을 이해할 수 있긴한데 그러면 겉핥기식 이해 밖에 안되므로 어셈블리어 공부를 어느정도 하시고 이 글을 읽는걸 추천드립니다.
스택 프레임에 대한 간단한 설명들은 인터넷에도 많이 나와있으므로 참고 부탁드립니다 ^^.
글을 읽기 전 필요 선행 지식
- 인텔 32비트 어셈블리어 (x86 어셈블리어)
- 컴퓨팅 구조
:: 둘 다 자세히는 몰라도 되지만 어느정도는 알아야 합니다.
- C언어 지식 (C언어는 완벽히 다룰 수 있다고 가정하고 진행)
- 자료구조 (스택만 알면됨)
- 프로세스 메모리 구조 (C언어 동적 할당 부분에서 배우는 내용 숙지)
개요
스택 프레임의 이해에 앞서 간단하게 컴퓨터 구조에 대해 복습을 해보도록 하겠습니다.

우리가 프로그램 실행을 위해 HDD나 SSD 같은 저장장치에 저장되어 있는 실행 파일(*.exe) 을 더블 클릭해서 실행하면, OS(운영체제)의 Loader가 RAM(==흔히 메모리라고 함) 에 우리가 실행한 파일을 불러와서 적재하게 되고, CPU는 이제 RAM에서 프로그램의 코드를 읽어와 프로그램이 실행되게 됩니다. 본격 글 복붙하기

현대 컴퓨터 구조에 의해 모든 실행중인 프로그램, 즉 프로세스는 RAM위에서 실행되게 되는데 이것들은 아무 구조 없이 메모리로 올라가는게 아닙니다. 각 프로세스들은 OS로부터 메모리 공간을 할당받아, 특별한 메모리 구조를 가지고 RAM위에서 실행됩니다.
프로세스마다 저마다의 방(메모리 공간)을 배정받고 그 방을 나눠서 효율적으로 사용한다(Code, Data, Stack, Heap Section)고 생각하면 이해가 쉽습니다.
프로세스의 메모리 공간은 크게 4가지로 분류됩니다. [자세한 설명]

코드 영역(TEXT) : 프로그램 실행 코드가 저장되는 영역입니다. (.text나 텍스트 영역이라고도 함)
스택 영역(STACK) : 함수 호출에 의한 매개 변수와 지역 변수, 그리고 함수, 반복문, 조건문 등 중괄호 내부에 정의된 변수들이 저장되는 영역으로 잠깐 사용하고 메모리에서 소멸시킬 데이터가 저장되는 영역입니다. 자료구조 스택과 연관이 있습니다.
데이터 영역(DATA) : 전역 변수와 정적 변수들이 저장되는 영역으로 프로그램이 종료될 때까지 유지되어야 하는 데이터가 저장되는 영역입니다.
힙 영역(HEAP) : 프로그램이 실행되는 동안에 프로그래머가 동적으로 메모리를 할당할 수 있는 영역으로, 프로그래머가 마음대로 사용할 수 있는 영역입니다. (대신 프로그래머가 수동으로 관리해야함.) 자료구조 힙과는 연관이 없습니다 [주의]
이 4가지의 영역중에 우리가 볼 주요 TOPIC이 바로 스택 영역입니다. 다른 영역은 무시하셔도 됩니다.오늘은 이 스택 영역을 자세히 살펴볼 겁니다.
스택 영역 (스택 메모리)

스택 영역은 아주 쉽게 말해서 지역 변수(Local Variable) 들이 저장되는 영역입니다. 지역 변수라고 하면 중괄호 내부에서 선언된 모든 변수들을 의미합니다. 지역 변수는 중괄호를 나가면 메모리가 소멸하게 되는데, 이게 바로 스택 영역에서 메모리를 소멸시키기 때문입니다. 함수의 매개변수 역시 함수 내부에서 선언되어 있는 지역변수입니다.
그리고 스택 영역이라는 이름에서도 유추해보셨겠지만 프로세스 메모리 구조에서 스택 영역은 바로 자료구조 "스택" 을 활용하여 메모리를 관리하는 영역입니다. 보통 스택이라고 하면 데이터가 아래서 위로 접시를 쌓듯이 쌓이는 구조입니다.
접시가 아래에서 위로 쌓여있으면, 접시를 깨뜨리지 않고 빼기 위해선 바로 위에서 빼는 방법밖에 없죠?
스택이라는 구조는 데이터의 삽입과 삭제가 TOP이라고 하는 꼭대기에서만 일어나게 됩니다.
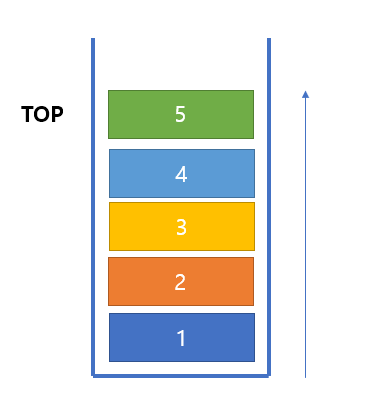
당연히 이 글을 읽는 분들은 스택 구조 정도야 아실꺼니깐.. 더 자세한 설명은 하지 않도록 하구요. 보통 자료구조 시간에 배운 스택을 떠올리면 데이터가 아래에서 위로 차곡 차곡 쌓이는 그림을 연상하실껍니다. 그렇죠?

그런데 프로세스 구조에서의 스택은 아까 그림을 다시 보면 알겠지만 화살표 방향이 아래로 가있습니다.
프로세스 메모리 구조에서 스택 영역은 우리가 아는 스택을 거꾸로 돌려놨다고 생각하시면 이해하기가 편합니다.
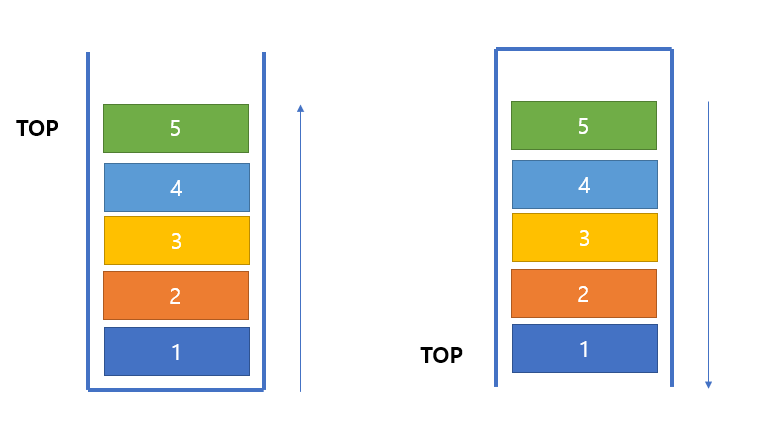
즉 왼쪽 그림이 아니라 오른쪽 그림처럼 스택이 뒤집혀서 위에서 아래로 자라나면서 데이터가 추가되고 있는 것이죠.
방향만 바뀌었을 뿐입니다.

추가적으로 힙 영역을 보시면 Heap은 화살표 방향이 아래서 위로 자라나게 되어 있습니다. (스택 영역과 반대)
만약에 스택 영역에 데이터를 너무 많이 저장하다보면 스택이 위에서 아래로 자라나다가 아래서 위로 자라나는 힙 영역와 충돌하는 문제가 발생할 수 있습니다. 이게 바로 우리가 흔히 말하는 Stack OverFlow 입니다. 스택 영역이 꽉차서 Heap과 충돌하여 데이터 오염(충돌)이 발생하여 프로그램이 강제 종료되게 되는 것이죠.
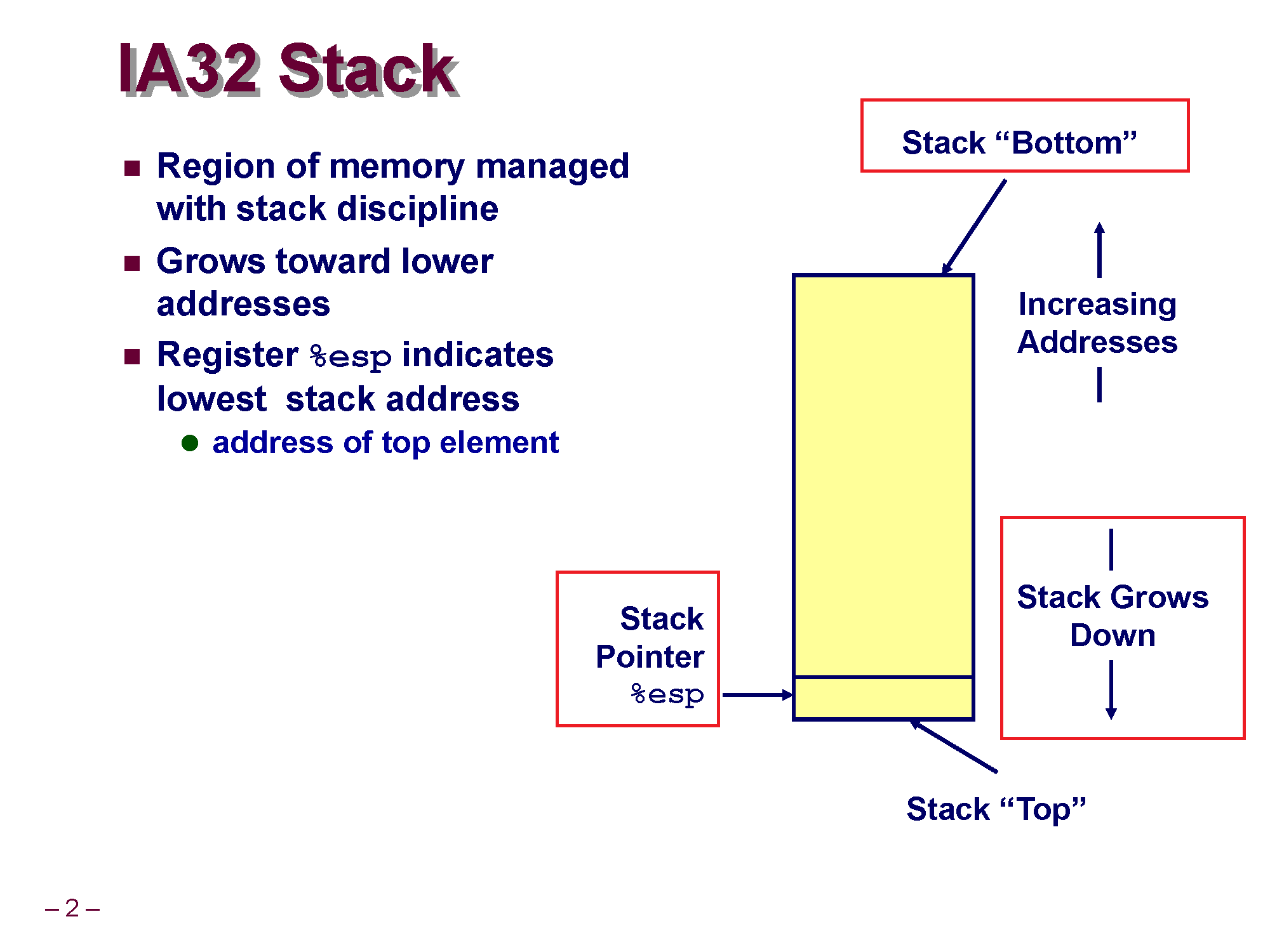
위에서 봤던 프로세스 메모리 구조의 스택 영역을 그림으로 도식화 하면 위와 같습니다.
방금도 언급했듯이 스택이 90도 돌려져서 그려져 있기 때문에 데이터가 아래로 자라나며 (Stack Grows Down), Stack의 Top 은 아래에, Stack의 Bottom은 위에 그려지게 됩니다.
(사실 그냥 스택을 각도만 돌려놓은게 다입니다.)
스택에 데이터를 삽입 & 삭제하는 연산은 스택의 꼭대기인 Top에서 이루어지게 되는데요. 컴퓨터 입장에선 스택 메모리에 데이터를 담기 위해 Stack의 Top을 항상 기억하고 있어야 합니다. 그리고 이런 역할을 하는게 바로 CPU의 ESP 레지스터 입니다.
ESP(Extended Stack Pointer Register) 는 Stack Pointer Register란 이름 그대로 항상 스택의 Top 주소를 저장하여 가리키며, Top의 위치를 기억하는 역할을 하게 됩니다.
스택 메모리에 데이터를 삽입하거나 삭제할 때 CPU는 이 ESP 레지스터 값을 활용하여 스택 메모리에 접근하게 됩니다.
현재는 스택이 비어있는 상태라 조금 심심한 상태인데, 이제 어셈블리 명령어를 통해 CPU에 명령을 내려 스택 메모리에 데이터를 한번 추가해보도록 하겠습니다.
push & pop 명령어
push src위 명령어를 사용하면 스택에 src 라는 내용을 삽입(push)할 수 있습니다.
어셈블리 명령어 push src를 실행하면 src 값을 스택 메모리에 Push 한 후, ESP 레지스터의 값을 4만큼 감소 시킵니다. (-4)
* src는 4바이트 크기라고 가정
src라는 값을 스택 메모리에 넣는건 대충 이해가 되는데 왜 ESP 레지스터의 값을 4만큼 감소시키는 걸까요?
push 123위 명령어를 실행시켰다고 가정하고 한번 스택의 모습을 관찰해보겠습니다.

push 123 명령어를 실행하면 "123" 이라는 숫자를 4바이트로 취급하여 스택의 Top에 Push 하게 됩니다.
123이야 그냥 DRAM에 쓰면 되지만, ESP 레지스터의 경우 사정이 다릅니다.

ESP 레지스터는 본래 빈 스택의 Top 부분을 가리키고 있었습니다. 이 주소를 0x1000 이라고 한다면 ESP 레지스터엔 초기 0x1000이 저장되어 있었습니다.
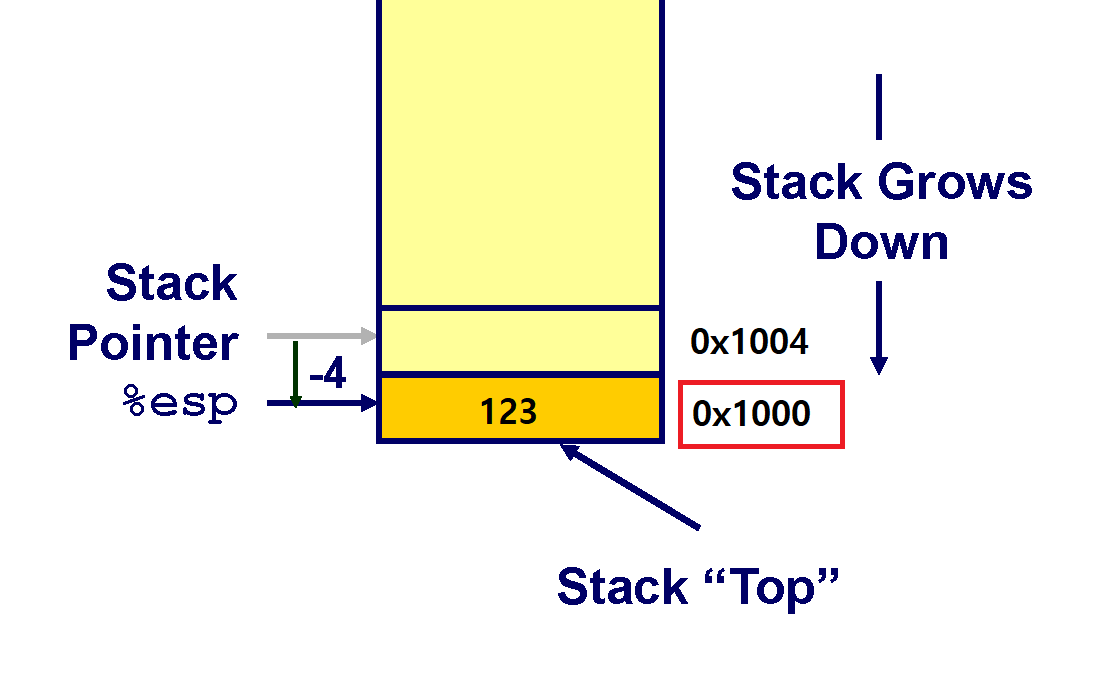
그런데 이렇게 데이터를 삽입하게 되면 123이 스택의 Top에 삽입되게 되면서 스택의 Top 주소가 0x1000으로 바뀌게 됩니다. ESP 레지스터는 아까도 말했듯이 스택의 Top을 항상 가리키고 있어야 합니다. 현재 스택은 아래로 자라나고 있으므로, 주소의 입장에선 감소를 하게 된 것입니다.
그러므로 ESP 레지스터가 Stack의 Top을 가리키기 위해선 (4바이트 크기의 데이터를 삽입했으므로) 현재 자신의 값에서 4를 빼야 Top의 위치를 가리킬 수 있게 됩니다.
이처럼 스택은 주소가 감소하는 방향으로 증가하게 됩니다.
스택에 데이터를 삽입하면 스택의 데이터는 아래로 자라나고, 주소 값은 감소하게 됩니다.
이에 따라 유추해볼 수 있지만 반대로 스택은 주소가 증가하는 방향으로 감소하게 됩니다.
반비례 관계라고 생각하시면 됩니다.
스택이 감소하는 예제도 아래 사진으로 확인해봅시다.

pop destpop 명령어를 사용하면 스택 메모리의 Top에서 데이터를 빼서 dest 위치에 저장할 수 있습니다.
pop 명령어를 수행해서 스택 메모리에 저장된 123이라는 값을 빼냈고 Stack의 Top은 위로 올라가게 됩니다.
스택이 줄어들었으므로, 메모리 번지는 증가하게 됩니다.
pop 명령어를 수행하면 dest 위치에 스택의 Top의 내용을 뽑아 Dest에 저장하고, ESP 레지스터의 값을 4 증가시킵니다.

스택에 무언가 삽입하면 주소가 감소한다는 개념이 조금 생소하시죠?
위 사진을 보고 스택 메모리의 동작에 대해 조금 더 이해해봅시다.
Step1, Step2, Step3 를 순서로 push, pop 명령어를 수행하면서 레지스터와 스택 메모리의 변화를 보여주는 예제입니다.
Step1 - 우선 초기 상태로 이미 스택 메모리엔 123이 push되어 있고, eax, edx, esp 의 레지스터에 값이 저장되어 있습니다. 현재 Stack의 Top은 요소가 "123" 이라는 숫자 하나이므로 0x108 주소가 바로 Top의 주소입니다.
보다 싶이 ESP 레지스터에 스택의 Top 주소가 저장되어 가리키고 있음을 알 수 있습니다.
Step2 - 이제 push eax 명령어를 실행해서 eax 레지스터의 값을 스택 메모리에 추가하게 됩니다.
eax 레지스터에 213이 저장되어 있으므로 스택 메모리엔 213이 push 되게 됩니다.
push 명령어를 수행했으므로, 스택의 데이터가 아래로 자라나 213이 Top위치에 Push되고 주소는 감소하게 됩니다.
Top의 위치가 4만큼 감소했으므로, ESP 레지스터의 값 역시 4만큼 감소해서 Top을 가리키고 있음을 알 수 있습니다.
Step3 - 마지막으로 pop edx 명령을 통해서 스택 메모리의 Top 값을 빼내서 edx 레지스터에 저장하게 됩니다.
현재 Top 값이 213이므로 스택에서 213 값이 빠지게 됩니다. 스택 내용이 감소했으므로 Top의 주소는 증가하여, ESP 레지스터는 4만큼 증가해, 변화한 Top의 주소 0x108을 가리키고 있음을 알 수 있습니다.
이처럼 esp 레지스터는 push & pop 명령어를 수행할 때마다 자동으로 증가하거나 감소하여 항상 스택의 Top을 가리키게 됩니다.
call 명령어
int sum(int a, int b)
{
return a + b;
}C언어에서 위와 같이 sum 함수가 작성되어 있다고하면 호출(실행) 하는 방식은 아래와 같습니다.
int result = sum(1,2);sum(1,2) 와 같은 형태로 코드를 작성하면 1과 2라는 인자값이 함수 sum의 매개변수 a, b로 복사되어 sum 함수 내부의 코드를 실행 한 후, 리턴 값을 함수 위치로 던져서, result엔 1과 2의 합이 저장되게 됩니다.
우리에게 아주 익숙한 함수의 개념입니다. 어떤 코드 뭉치에 이름을 붙인 후에 입력값을 받아서 코드를 실행하고, 출력값을 반환하는 기능을 수행하죠.
우리가 작성한 C언어 코드를 컴파일 하면 먼저 C 코드를 어셈블리어로 바꾼 후, 어셈블러를 통해 최종적으로 어셈블리어를 기계어로 변환하게 됩니다.
C언어에서 작성한 함수 호출은 어셈블리 레벨에서 어떤식으로 변환이 되는걸까요? 어셈블리어가 Low-Level에서 동작하는 언어이므로 jmp 명령어로 코드 위치로 뛰어서 push, pop 명령어를 통해 스택 메모리를 활용해서 함수를 실행한다고 예측해볼 수 있습니다만.. 실제로 어셈블리어에선 call 이라는 명령어를 통해 함수 호출을 간단하게 할 수 있는 기능을 제공하고 있습니다..!

call label 명령어를 실행하면 label 위치로 점프를 해서 그 위치부터 코드를 실행하게 됩니다. 꼭 label이 아니여도 404000 주소 위치에 함수 코드가 있따면, call 404000 와 같은식으로 호출하면 404000 위치의 코드를 실행시키게 됩니다.
설명만 들어오면 jmp 명령어랑 무슨 차이가 있나 싶지만 실제로 call 명령어는 2가지 일을 수행합니다.
call label 을 실행하면 1. 우선 돌아올 반환 주소(Return Address) 를 스택에 Push하고 2. label 으로 jump 해서 코드를 실행합니다.
여기서 중요한점은 jmp 명령어랑은 다르게 돌아올 반환주소를 자동적으로 스택에 Push 한다는 점입니다.
call 명령어는 한마디로 push + jmp 명령어를 하나로 축약해서 사용할 수 있는 간편한 명령어 입니다.
label로 점프해서 코드를 실행하는건 알겠는데 과연 저 Return Address를 스택에 삽입한다는건 무슨 뜻일까요?
foo()예를 들어서 foo() 라는 함수를 C언어에서 호출했다고 생각해보겠습니다. 그러면 컴파일러에 의해 일단 C언어는 1차적으로 어셈블리어로 변환될 것인데요. C언어에서 호출한 함수 foo() 는 실제로 어셈블리어의 call 명령어로 변경될 겁니다. 그렇겠죠? foo 라는 함수 코드가 메모리(DRAM) 상의 8048b90 이라는 주소에 올라왔다고 가정해 봅시다.
그러면 실제로 C언어에서 작성한 foo() 라는 코드는 어셈블리 레벨에서 call 8048b90 가 될겁니다.

현재 컴퓨터는 call 8048b90 을 통해 foo 함수를 호출해서, foo의 코드를 실행시켜야 할 차례이며 또 push %eax 명령어를 실행시켜야 합니다.
CPU는 8048b90 의 코드를 실행시킨 후 , foo의 함수 코드가 종료되면 다시 foo 함수 코드 위치 다음으로 이동해서 push 명령어를 실행시켜야 합니다.
한마디로 컴퓨터는 call foo 를 한 후에 리턴된 후, call의 다음 명령어 주소로 돌아와서 또 push %eax 명령어를 실행시켜야 된다 이말입니다.
컴퓨터는 이를 위해 call 8048b90 을 통해 call 명령어로 foo를 호출한 순간 call 명령어 다음에 실행될 명령어 push %eax의 주소 8048553을 스택메모리에 우선 push 합니다. -- call 다음에 실행될 명령어의 주소 8048553은 바로 EIP의 주소입니다. EIP는 현재 명령어를 실행 후 바로 다음에 실행할 명령어의 주소를 가리키고 있으니깐요. 그리고 8048b90 로 뛰어서 foo를 실행한 다음 foo 함수의 코드 실행이 끝나서 반환(Return) 되면 아까 스택 메모리에 백업해뒀던 Return Address[8048553] 을 다시 pop 해서 가져온 뒤 이 위치로 돌아와서 다음 코드 push %eax를 실행하게 됩니다!
void foo(){
//...
return
}
int main(){
foo();
push();
}우리에게 익숙한 C언어로 나타내면 이런 흐름이 될 겁니다. foo 를 호출하면 foo의 코드가 실행되고, return 되고 돌아와서 push() 를 실행하는 형태죠. 당연히 위에서 아래로 컴퓨터는 코드를 실행시키기 때문에 이런 흐름이 되어야 할 것입니다.
즉 call 명령어의 동작을 정리하면 아래와 같습니다.
call [함수주소] == push eip + jmp [함수 주소]
call 을 실행하면 call 다음에 실행할 코드 주소, 즉 EIP 레지스터의 값을 스택에 백업한 후 , jmp 를 통해 함수 주소로 점프해 함수 코드를 수행한다!
위에선 자세히 설명드리진 않았는데 여기서 EIP 값을 Return Address 라고도 합니다. 함수 호출 후 돌아와서 다시 실행할 반환 주소(Return Address) 가 바로 EIP의 주소가 되는 것이지요.
그리고 앞에서 배운 내용으로 예측해볼 수 있겠지만 call 명령어를 실행하면 push eip를 통해 eip값을 스택 메모리에 Push 하기 때문에 스택의 TOP을 가리키는 ESP 레지스터 값도 변하게 될겁니다. 스택 메모리의 내용이 증가했으므로 ESP 레지스터의 값은 4만큼 감소하겠네요!

그리고 foo() 함수 내부에서 코드 실행이 끝나서 return 되는것을 단순히 "리턴된다" 라고 표현했는데요.
실제로 함수 내부에서 return 해서 돌아가는 것에 해당하는 어셈블리 명령어가 있습니다. 바로 ret인데요.
ret 명령어는 앞에서 본 call 명령어와 짝으로 사용할 수 있는 명령어인데, 똑같이 2가지 기능을 합니다.
1. 아까 전에 백업했던 eip 레지스터 값(Return Address)을 스택에서 Pop한다.
2. 백업해둔 EIP 레지스터의 값이 곧 함수 호출 이후 다음 실행할 주소, 즉 Return Address이기 때문에 jmp [Return Address]를 통해 점프 해서 다음 코드를 실행시킨다.
void foo(){
//...
return // == RET
}C언어로 치자면 foo 함수 호출 이후 return 해서 함수 종료 하는 코드가 어셈블리어론 RET 라는걸 이해할 수 있습니다.
(물론 C언어에서 void 함수는 다 실행해서 종료할때가 되면 저렇게 return 을 명시적으로 안쓰고 생략해도 return이 자동으로 붙어서 컴파일 되긴 합니다.)
어 그럼 C언어에서 return 10; 같은건 어떻게 해요? RET 명령어엔 리턴값을 줄 수가 없는거 같던데.. 라는 궁금증이 생기시죠? 실제로 어셈블리 레벨에선 함수의 반환값을 RET 명령어 전에 레지스터에 저장하게 됩니다. 함수의 반환값을 저장하는 레지스터는 바로 EAX 레지스터인데 함수의 리턴값은 RET 명령어 전 mov eax, 10 과 같은 형태를 통해 EAX 레지스터에 값을 저장해 리턴값으로 사용하게 됩니다.
RET 명령어에 의해 함수 호출이 끝나서 돌아오게 되면 우리는 함수 호출 이후 바뀐 EAX 레지스터의 값을 보고 아 이게 리턴 값이구나! 하고 사용하면 됩니다.
* 물론 꼭 eax 레지스터에 저장하지 않아도 함수의 반환값은 push 명령어를 통해 스택 메모리에 보존해서 줄 수도 있습니다.
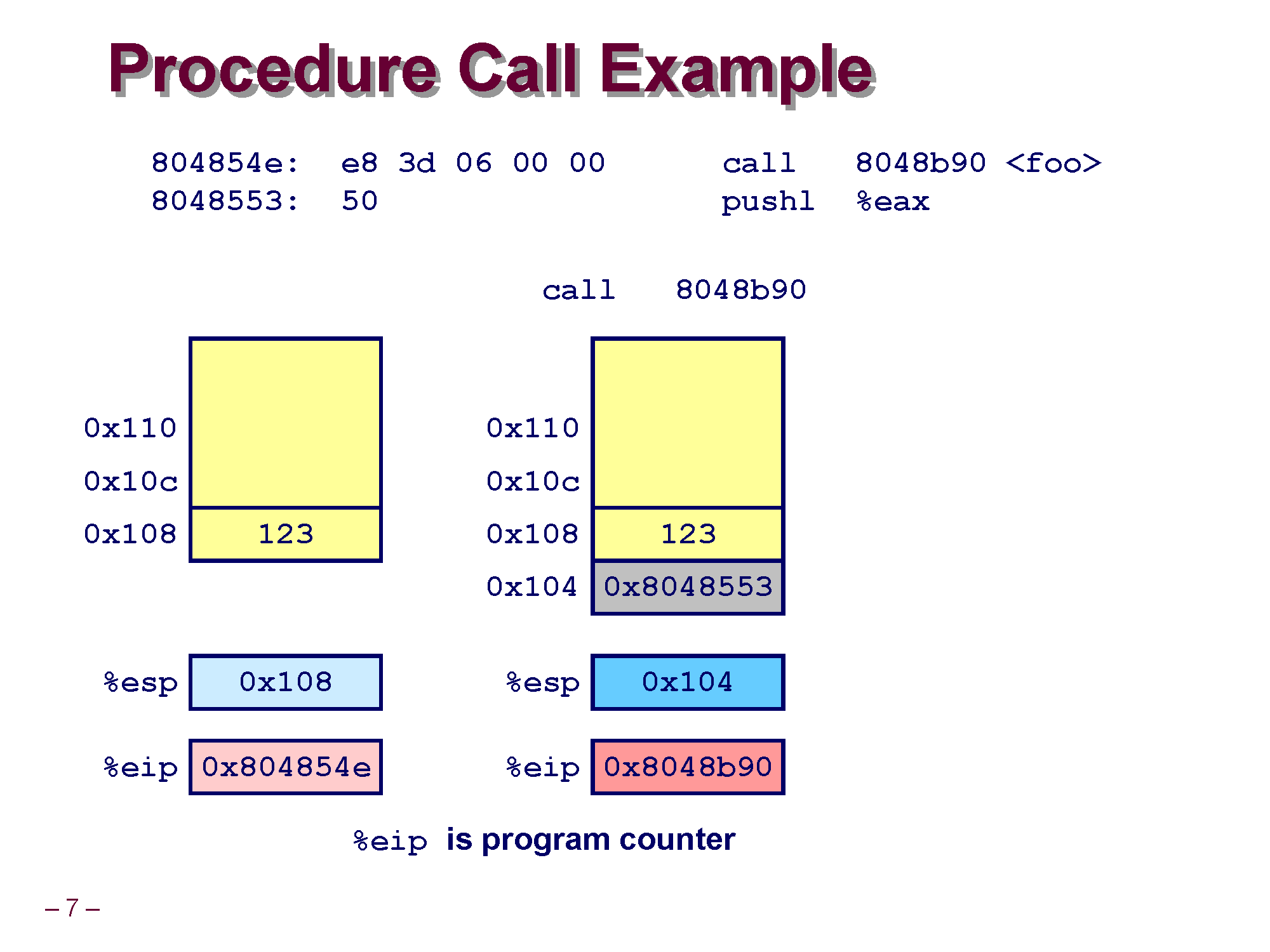
함수의 호출 과정을 스택 메모리 + 레지스터의 그림으로 함께 보면서 이해도를 조금 더 높혀보겠습니다.
1. 우선 초기 call 8048b90, 즉 foo를 호출하는 코드 실행 이전의 상태는 왼쪽 그림과 같은데
123이 이미 스택 메모리에 push 되어 있고 ESP 는 stack의 top인 0x108 (123 데이터의 주소) 를 가리키고 있으며, EIP는 현재 call 명령어를 실행하기 위해 0x804854e 가 저장되어 있습니다. [물론 아직은 0x804854e 주소의 명령어를 실행시키진 않은 상태입니다)
현재 CPU가 이제 명령을 읽기 시작하면 EIP 레지스터(Program Counter)의 값 0x804854e 의 코드를 실행시키게 됩니다.
2. CPU가 명령어를 실행해서, call 8048b90 을 실행한 순간 call 명령어는 현재 call 명령어 다음에 돌아올 주소, 즉 call 명령어 바로 다음의 주소 값인 0x8048553을 스택 메모리에 push 하고 jmp 8048b90 을 실행하게 됩니다.
jmp 명령어는 알다 싶이 EIP 레지스터의 값을 바꿔서 그 위치부터 프로그램을 실행시키게 하여 실행 흐름을 바꾸는 명령어 입니다. jmp 8048b90 을 수행시킨 순간 eip 레지스터 값이 8048b90로 바뀌어서 이제 foo의 함수 코드인 8048b90 의 주소 위치부터 코드를 실행시키게 됩니다.
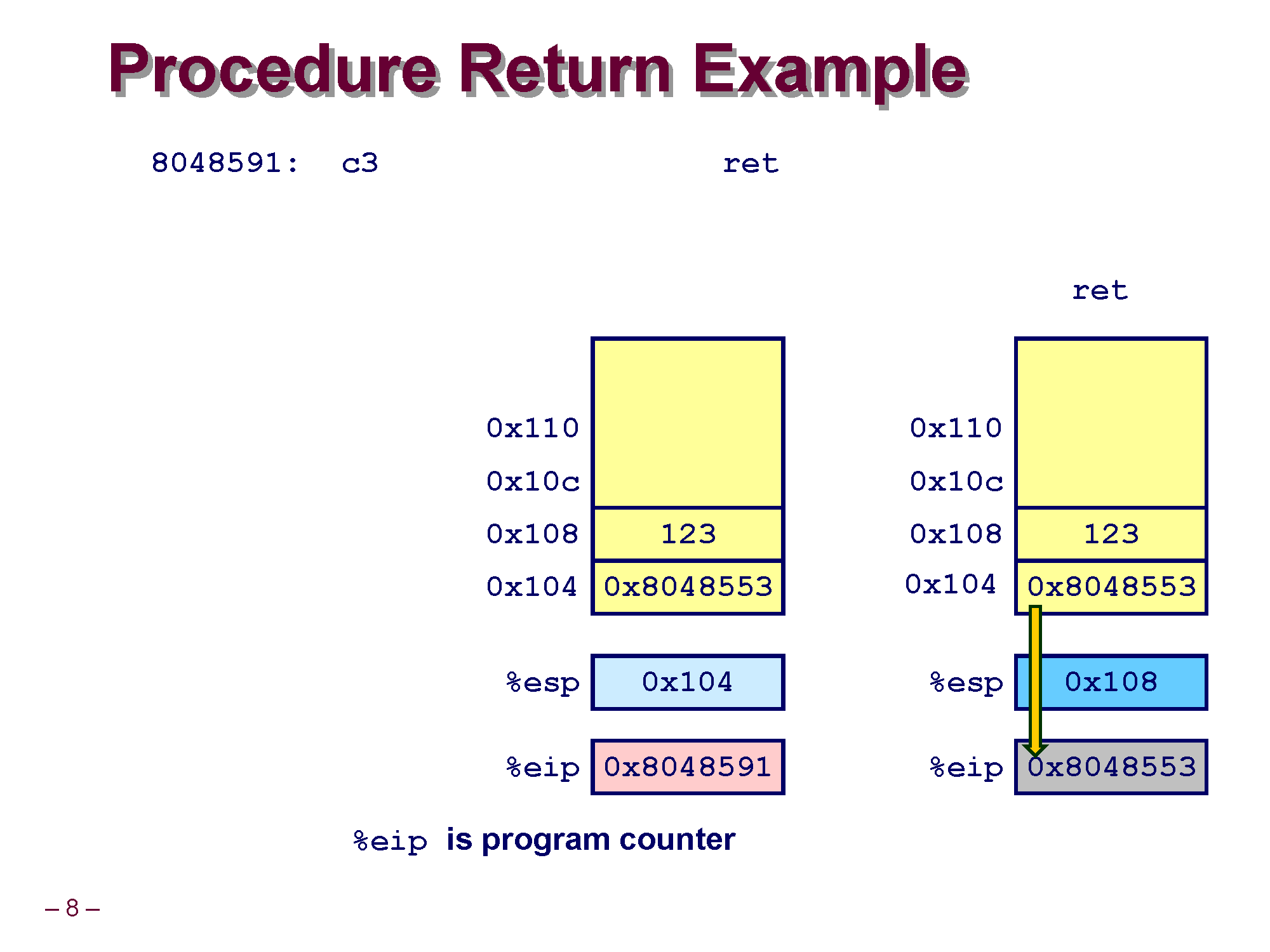
foo() {
//...
ret <-- 8048591
}3. foo의 함수 코드 실행이 끝나고 foo 함수 안에서 return 하기 위해 RET 명령어를 실행하는 시점이 왔습니다.
EIP 레지스터는 현재 0x8048591 을 가리키고 있습니다.
4. RET 명령어를 실행시켰습니다. 알다 싶이 RET 명령어는 방금전에 push한 return address 값(백업한 eip 레지스터값)을 pop 해와서 jmp 시키는 명령어 입니다. 보시다 싶이 0x8048553 으로 돌아가서 다시 foo 함수 호출 이후에 명령어를 실행시켜야 하므로 eip 레지스터는 jmp에 의해 0x8048553로 변경된 이후 이 위치로 돌아와서 다시 코드를 실행시키게 됩니다.

5. call 이후 돌아와서 EIP 레지스터는 8048553 이 되어 이제 push eax 명령어를 실행시키게 됩니다.
사실 중간에 EIP 레지스터 값이 변하는거나 스택 메모리를 크게 신경쓰지 않으면 우리가 흔히 보던 C언어의 코드 실행 흐름과 똑같다는걸 알 수 있습니다. 실제로 CPU가 내부적으로 동작하는 사정을 더 깊게 이해하게 된 겁니다.
스택 기반 언어

실제로 많은 프로그래밍 언어가 이 "스택" 개념을 이용해 코드를 작성할 수 있게 해줍니다. ex) C, Pascal, Java
거의 대부분 아니 모든 언어가 지원한다고 해도 과언이 아니겠네요.. 왜냐면 프로세스 메모리 영역 자체에 스택 영역이라는 것을 두었고 모든 프로그램이 기계어(어셈블리어) 로 변역되니깐요 -.-
어쨌던 프로세스 메모리 영역인 "스택 영역"
편의상 스택으로 부르자면
이 스택에 저장되는 것은 아래와 같습니다.
1. 지역 변수
2. 함수로 전달된 인자 (함수 인자가 사실상 지역변수라 1번에 해당되는 것임)
3. 함수가 돌아갈 위치 (위에서 확인한 Return Address)
또한 앞에서 설명드리진 않았지만 스택은 1개 또는 그 이상의 "프레임" 으로 구성되게 됩니다.
스택 프레임

드디어 등장한 메인토픽입니다. 시스템 소프트웨어 관련 글은 쓰면서 느낀건데 진짜 앞에 서론이랑 이해할게 뒤에 본론보다 몇배는 많은거 같네요 ㅎㅎ;
우선 이번에도 예제로 확인해볼건데 저희가 확인해볼 예제는 위와 같은 형태입니다.
yoo() 를 실행시킬건데 yoo() 안에선 who() 를 호출하고, who() 안에서는 amI() 를 2번 호출하고, amI() 에선 재귀 호출을 하게 됩니다.
이런 함수의 호출 단계를 Call Chain 이라고 합니다. 마치 체인이 연결되듯이 호출이 되고 있습니다.
앞에서 확인했듯이 함수를 호출할 때 인자값을 넘기려면 함수의 인자도 지역변수이므로, 지역변수가 저장되는 위치인 스택 메모리에 값을 저장하고, 함수가 돌아갈 위치(Return Address) 도 스택에 저장하고.. 함수 안에서 돌아가는 지역변수도 스택 메모리에 저장하게 됩니다.
그러니깐 결국엔 함수 호출을 하면 스택 구조를 활용한다 이거죠. 분명 C언어 배울때부터 간략하게 나마 배우셨을겁니다. 함수 호출 할땐 스택이라는 자료구조를 활용한다고요.. 그리고 앞 예제에서도 어떤식으로 동작하는지 보셨구요.
push & pop 을 해서 스택 메모리를 다루고 함수 호출할때 이용하는 방법도 알겠지만..! 여러 함수들이 스택 영역 안에서 메모리를 공유하면서 놀껀데 이 많은 함수들이 사용하는 인자나 지역변수를 어떻게 구분할까요?
함수들은 과연 스택에서 어떤 구조로써 다뤄질까요?
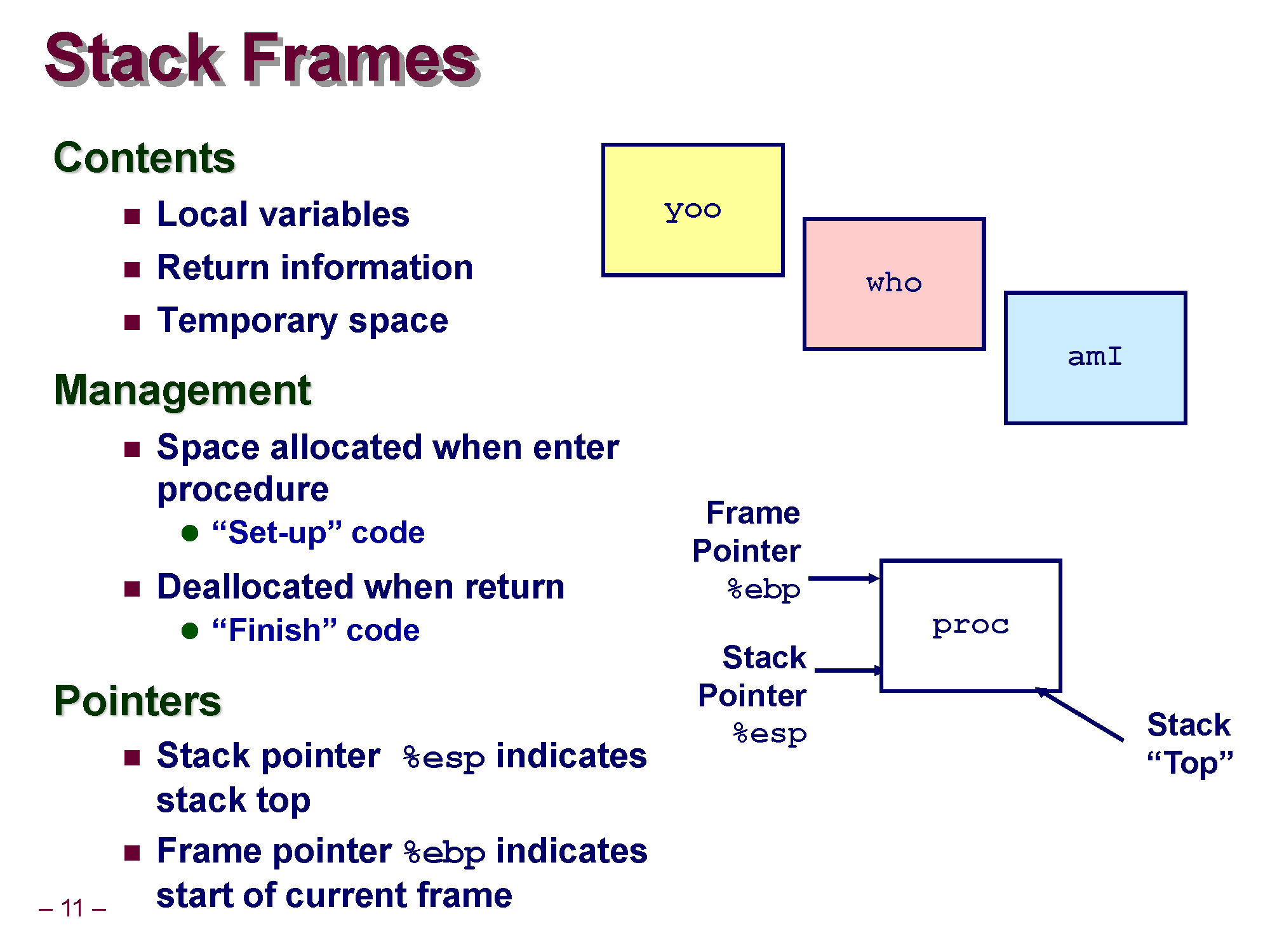
스택은 1개 또는 그 이상의 프레임으로 구성됩니다.
함수 호출 1회마다 각 함수 별로 이에 맞는 프레임이 메모리 공간에 잡혀서 생성되게 됩니다.
스택 프레임이란 함수가 호출될 때 그 함수 만의 스택 영역을 구분하기 위해서 생성되는 공간입니다.
함수 호출시 할당되는 메모리 블록이라고도 이해할 수 있습니다.

만약에 현재 proc() 라는 함수를 CPU가 실행중이라면 proc에 대한 스택 프레임이 먼저 잡히고 (그림으로 표시된 proc 네모 박스가 바로 proc() 함수에 대한 프레임입니다.), ESP가 현재 실행되는 함수의 프레임의 Top을 가리키게 됩니다. 또 이제 EBP라는 레지스터가 추가로 등장했는데 이 EBP 레지스터는 Extend Base Pointer Register로, 현재 실행중인 스택 프레임의 시작 주소(Base) 를 가리키게 됩니다.
시작 주소란 말이 햇갈리면 스택의 최하단, 가장 높은 주소를 가리키고 있다고 생각하셔도 됩니다. 스택 자체가 돌려져서 사용되다보니 Top이 아래 그려지고, Base(Bottom) 가 위에 그려지는 불상사가 일어났습니다만.. 머리속에서 90도 돌려서 EBP가 Base, 최하단이고 Top이 스택의 맨 꼭대기라고 상상해보세요 ㅎㅎ

다시 돌아와서 이 스택 프레임의 개념을 가지고 yoo() -> who() -> ami() 를 연쇄적으로 호출하면 함수가 호출되면서 동시에 그에 맞게 스택 프레임이 생성될 것인데, 이 흐름을 살펴보도록 하겠습니다.
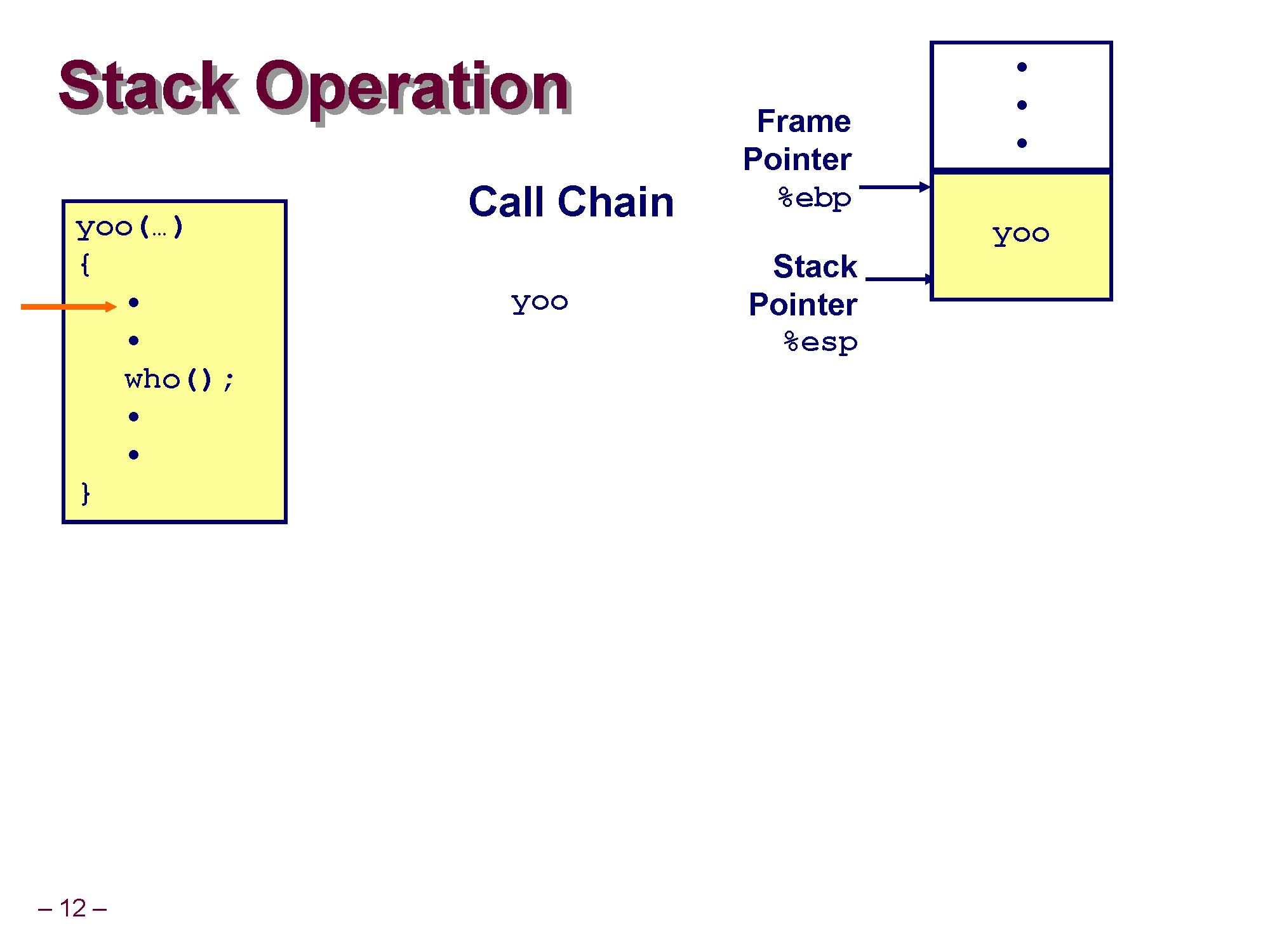
제일 처음 yoo() 를 호출하면 yoo가 사용할 수 있도록 메모리 공간을 할당, 즉 yoo에 대한 스택 프레임이 잡힙니다. 이때 yoo가 실행중이라 ESP 레지스터는 스택의 Top(yoo 스택 프레임의 꼭대기)을 가리키고, EBP레지스터는 yoo 스택 프레임의 시작 위치를 가리키게 됩니다.
코드가 쭈욱 실행되다가 yoo 안의 who() 를 만나서 컴퓨터 입장에선 우선 who() 를 실행시킨다음에 who() 의 실행이 끝나면 다시 yoo로 돌아와서 다음 위치의 코드를 실행시켜야 합니다.
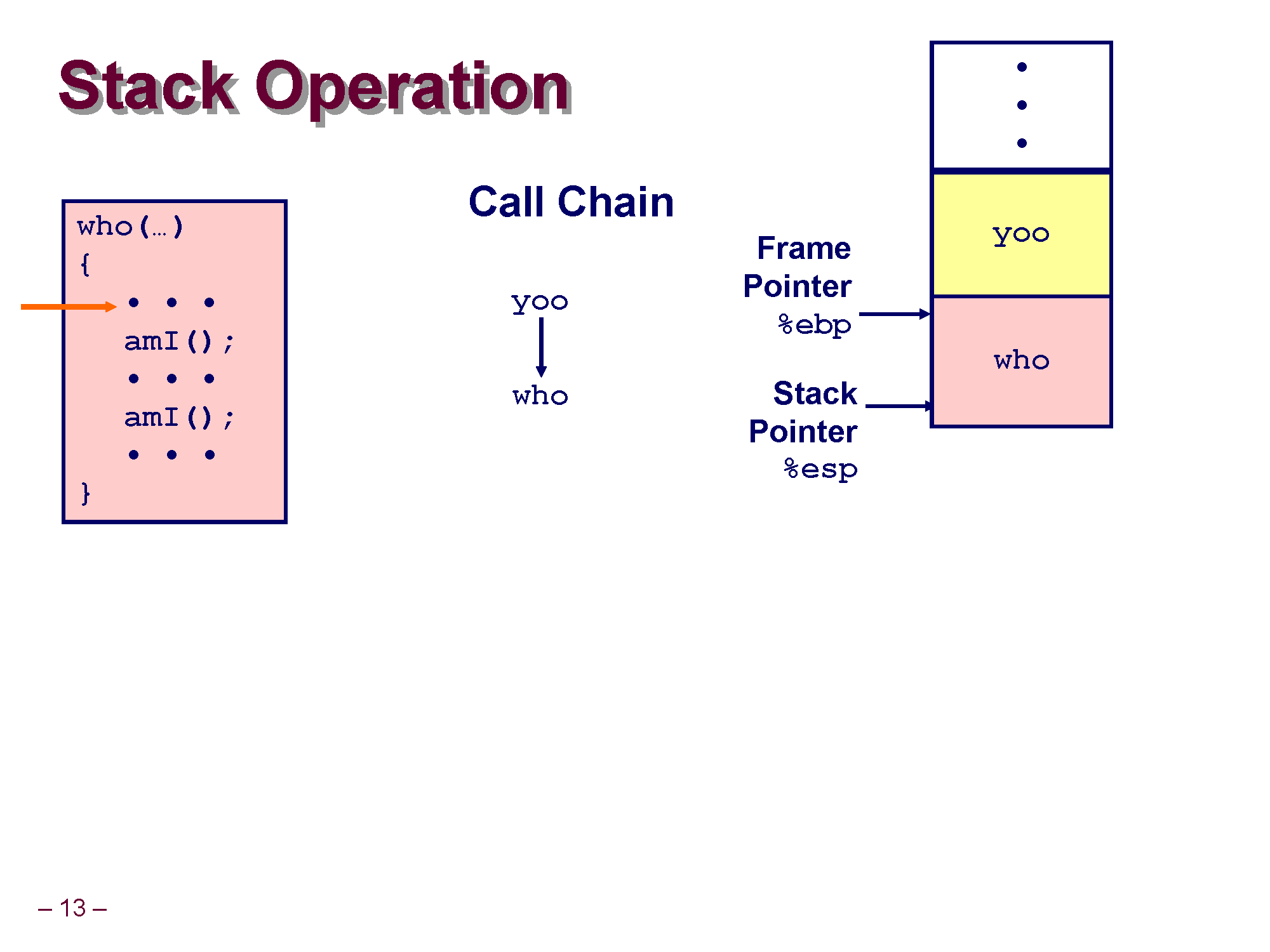
who() 를 수행하기 위해 who의 코드를 실행시킵니다. who가 호출되어 역시 who에 대한 스택 프레임이 생성되며, yoo 스택 프레임의 아래로 자라나게 됩니다. (아직 yoo 자체는 who 가 다 실행될때까지 기다려야 하기 때문에 소멸되면 안됨)
현재 실행되고 있는건 who이므로, 현재 호출되는 함수의 프레임의 시작을 ebp가, 끝을 esp가 가리키게 됩니다.
원래 yoo가 실행되다가 who가 실행되어 ebp와 esp가 옮겨진 것이며 주소상으론 둘다 감소(-) 하게 된 것입니다.
* 아까전의 스택 요소가 증가하면 주소가 감소하는 것과 일맥상통
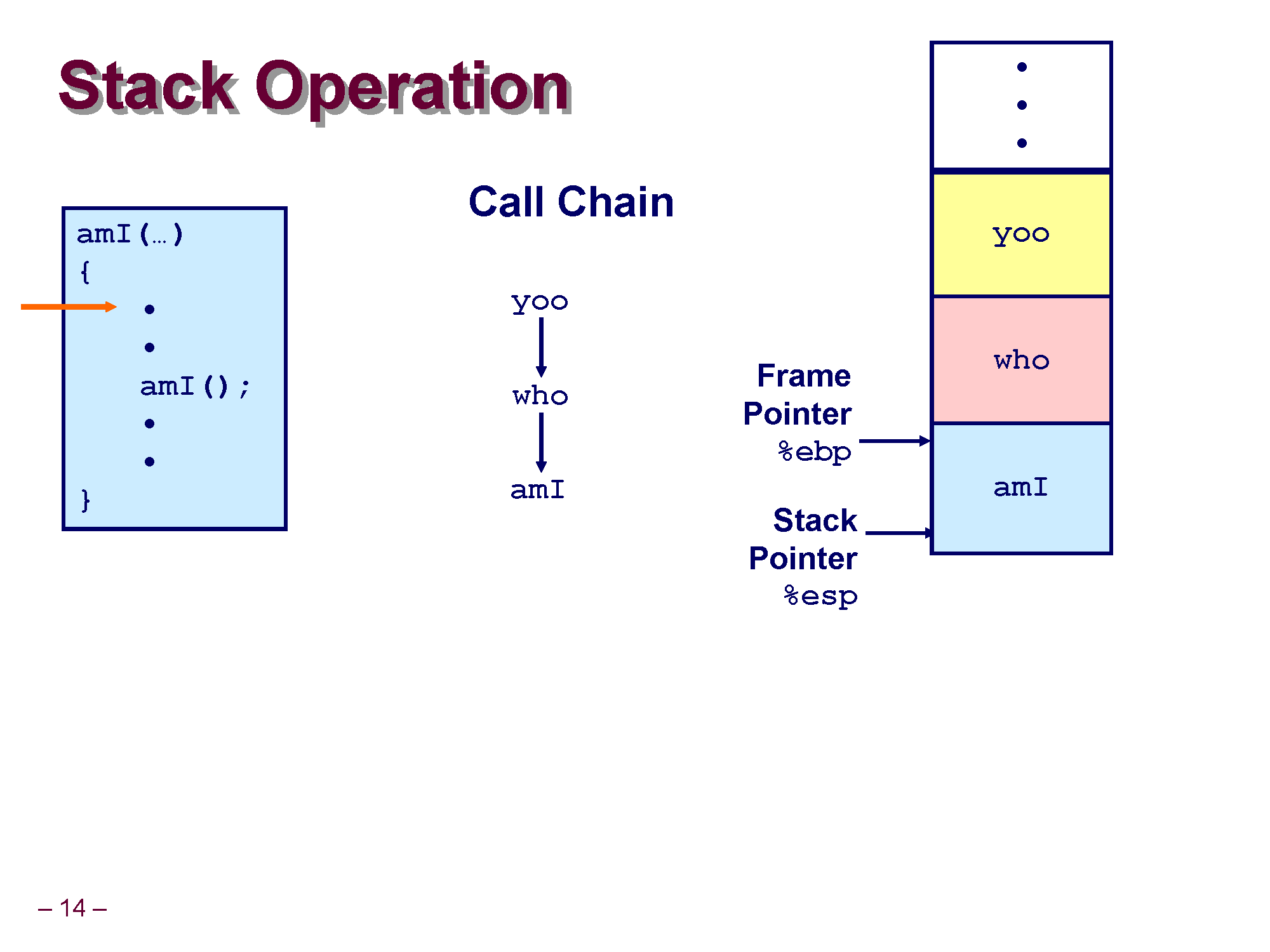
who 안에서 또 amI() 를 호출했으므로 이제 amI()에 대한 스택 프레임이 생성될 차레입니다.

amI() 가 호출되어 amI에 대한 스택 프레임이 잡히고 또 EBP와 ESP가 이동하게 됩니다. 그런데 amI() 가 수행될때 또 자기 자신이 자신을 호출하는 재귀 함수 호출이 이루어 지고 있습니다.
이렇게 되면 amI() 가 계속 호출될 것이고, 함소 호출 1회마다 각 함수 별로 스택 프레임이 생성되야 하므로 amI() 에 대한 스택 프레임이 계속 만들어지고 코드가 실행됩니다.

일단 amI() 안에서 재귀 함수의 종료 조건은 코드 상으로 생략했지만, 3번까지 호출하면 amI()는 종료된다고 가정해봅시다. 3번째 호출까지 들어와서 3번째에 호출된 amI() 에 대한 코드가 종료되었으며 이에 대해 실행되던 amI() 의 스택 프레임이 삭제되게 됩니다

바로 이렇게요. 이렇게 해서 3번째 amI()의 호출은 종료되게 되고 이제 2번째 amI() 호출로 돌아가서 3번째 amI() 를 호출한 코드 바로 다음 위치부터 다시 실행을 시켜야 합니다. 어떻게 3번째 amI() 호출 이후 돌아가나 싶지만, 아까도 확인했듯이 어셈블리 명령어 call 로 함수를 호출할 때마다 그 함수 다음으로 실행할 위치를 스택에 저장하고 있었죠.
실제로는 스택 프레임이 잡혀서 이 구조 안에 각 함수마다 이 함수가 끝나면 돌아갈 주소(Return Address)가 저장되고 있었던 겁니다. 어쨌던 스택 프레임 안에 저장된 3번째 amI() 스택 프레임 안의 Return Address값을 참조해서 2번째 amI() 호출 위치로 돌아가서 다시 코드를 실행합니다.
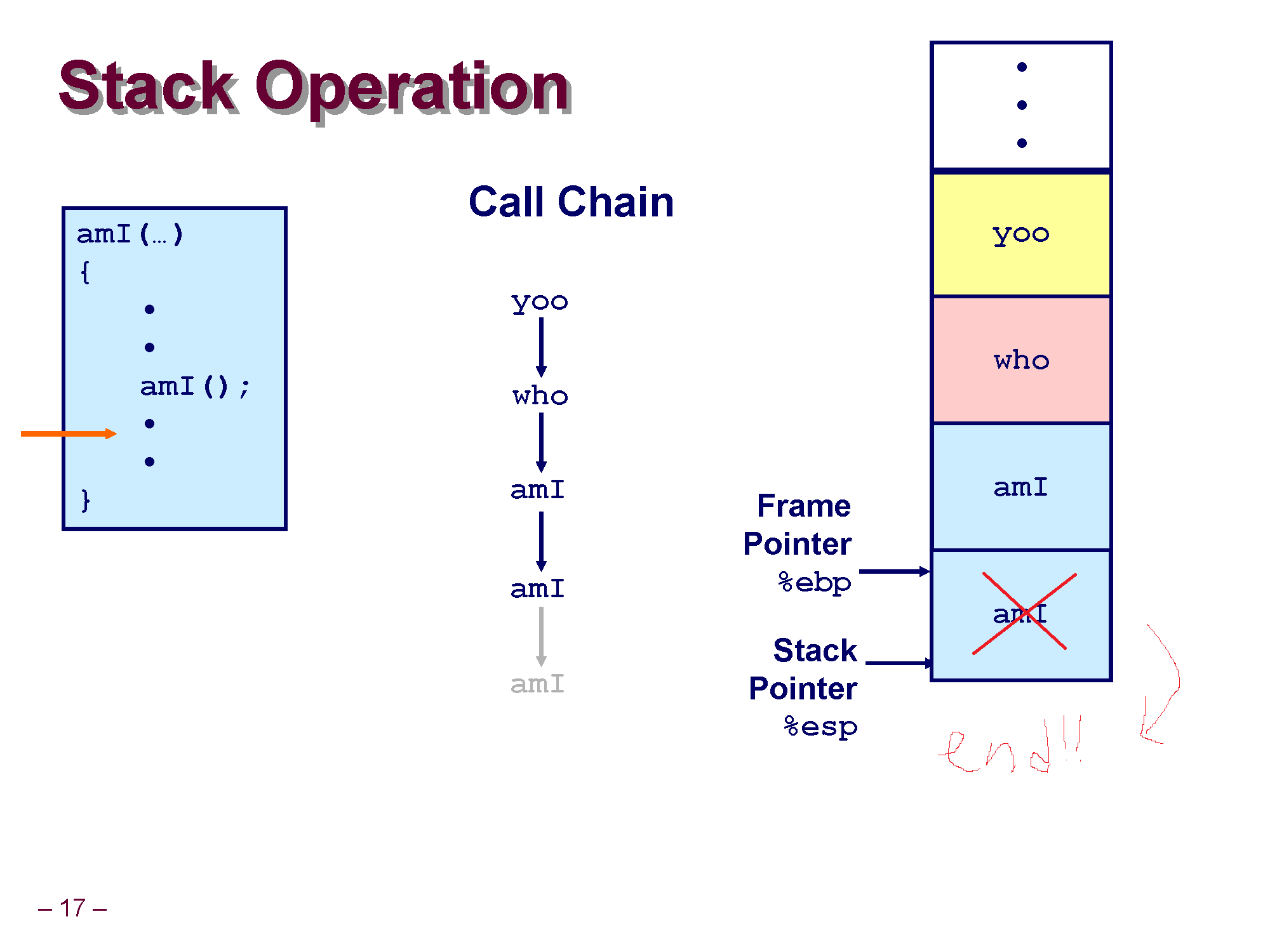
2번째에 호출된 amI() 의 경우 3번째에 호출한 amI()의 함수 호출이 끝나기를 기다리고 있었을 탠데, 3번쨰에 호출한 amI() 의 스택 프레임이 삭제된걸 보고 아 함수가 종료됐구나 하고 확인해서 이제 더이상 기다릴거 없이 본인의 코드가 종료되서 2번째 호출한 amI()의 스택 프레임도 삭제합니다.

이렇게 반복해서 amI() 재귀 호출은 모두 완료되었고 이제 who로 돌아와서 다시 코드를 실행합니다.
who 위치에선 amI() 를 2번째로 호출할 차례입니다.
amI() 가 who 안에서 또 다시 호출되고 재귀 호출이 반복되어 앞과 같은 상황이 반복됩니다. (생략)
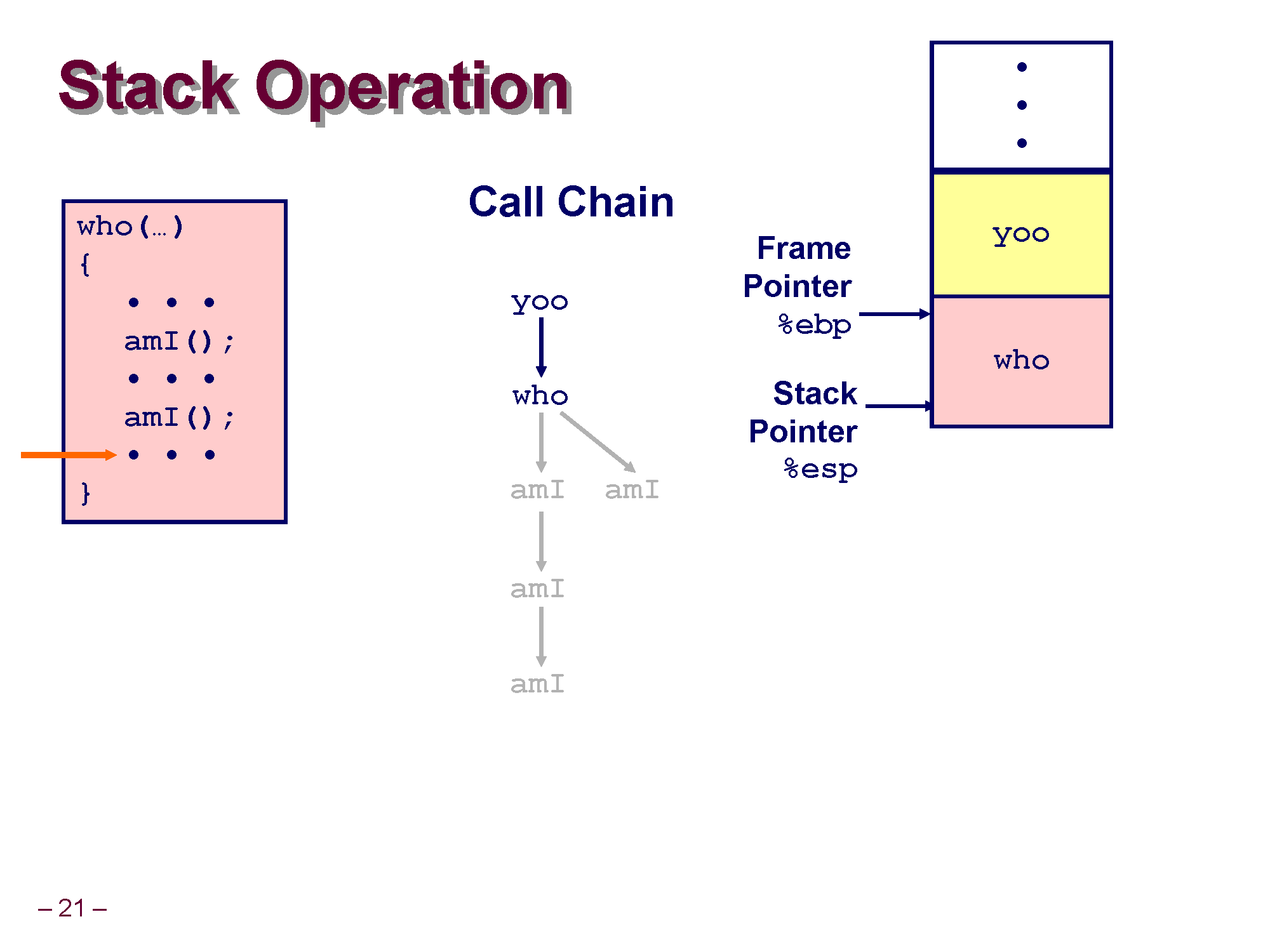
who 안에서 amI() 의 2번째 호출도 끝났고 이제 who는 더이상 실행할 코드가 없으므로 who의 실행이 종료되고 who에 대한 스택 프레임이 삭제됩니다.
이제 마지막으로 제일 처음 실행했던 yoo() 함수로 돌아옵니다.
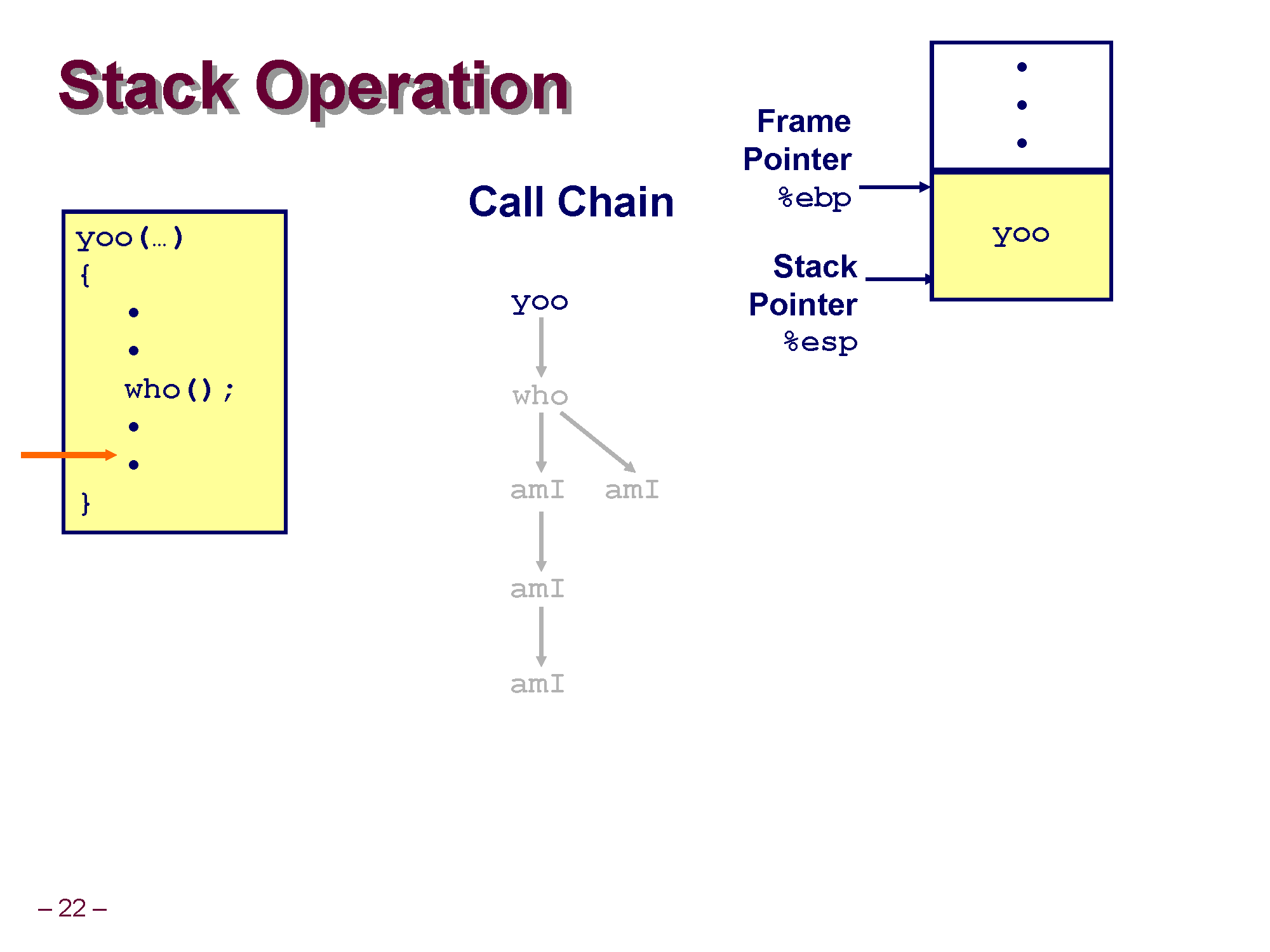
who() 의 실행이 끝나고 yoo는 역시 who() 다음 위치부터 다시 코드가 실행되는데 자신의 코드를 수행하고 종료되어 스택 프레임이 삭제됩니다. 최종적으로 스택은 비게 되고 길고 길었던 함수의 Call Chain이 끝맞춰지게 됩니다.
스택 프레임 2

앞에선 단순히 함수를 호출하면 그 함수에 대한 스택 프레임이 잡혀서 실행되고, 함수 호출이 끝나면 스택 프레임이 삭제되는걸 함수 이름이 적힌 네모박스로 간단히 소개드렸습니다만, 지금부터는 이 스택 프레임의 내부구조에 대해 자세히 알아볼겁니다.
위 사진에 보시면 알겠지만 콜러(Caller)와 콜리(Callee) 라는 용어가 나옵니다. Caller는 한국어로 번역하면 호출자 정도로 번역할 수 있는데, 어떤 A라는 함수가 B라는 함수를 호출하면 A라는 함수는 B라는 함수를 호출한 호출자(Caller)가 되고, B라는 함수는 A에 의해 호출당한 함수인 호출당한놈(Callee) 이 됩니다.
//Caller
int main(){
foo()
}
//Callee
void foo(){
}위 코드로 설명드리면 main 함수는 foo 함수를 호출한 콜러(Caller), 호출자가 되고
foo 함수는 main 함수에 의해 호출당한 콜리(Callee) 가 됩니다.
그렇게 어려운 개념은 아니죠?
사실 영어뜻 그대로인데 영어로 Employer는 고용주, 사장이 되는거고 Employee 는 고용당한 사람, 직원이 되는거랑 같습니다. 영어로 끝에 er~이 붙이면 무언가 하는 위치(?) 이고, ee가 붙으면 무언가 당하는 뜻이 됩니다.
뭐.. 위 사진에 대한건 역시나 예제로 보는게 빠를 거 같으니깐 Caller랑 Callee 라는 용어에 대해서만 정리하고 넘어가도 될 거 같습니다. 사실 별로 중요한 개념도 아닌 거 같고 -.- 전공서적 읽다가 당황하지 않으시라고 설명드렸습니다..

예제로 볼 것은 바로 C언어의 swap() 함수 입니다. 보통 포인터 처음 배울 때 Call by reference 라는 개념으로 정말 많이 배우는 함수이지요. swap 함수를 보시면 알겠지만 int 포인터 변수 2개를 이용해서 주소로 참조해 int 값 변수의 원본 값을 직접 바꿀 수 있도록 합니다.
cf) 참조하다 == 접근하다, 가리키다
이번 예제에서는 call_swap() 이라는 함수를 통해 swap() 함수를 호출해 int형 전역 변수 zip, zip2 의 값을 바꿀 수 있도록 합니다. call_swap() 이 여기선 caller, 호출당하는 swap() 이 callee가 되게 됩니다.
어쨌던 간에 이 프로그램에서 현재 call_swap() 함수를 먼저 실행시켰다고 가정하고 call_swap() 에 의해 swap() 이 호출될건데 이게 어셈블리 레벨에서 어떻게 동작하는지 보고, 스택 프레임이 어떻게 생성되는지도 살펴보겠습니다.

call_swap() 이 호출되면 call_swap에 대한 스택 프레임이 생성되고 이곳에 필요한 데이터들을 push 하게 됩니다.
call_swap() 에서는 swap을 swap(&zip1, &zip2); 와 같이 호출하고 j라는 지역 변수를 증가시키고 있습니다.
call_swap:
push zip2
push zip1
call swap
add...따라서 C언어 코드로 작성한 call_swap 을 어셈블리 코드로 바꾼다면 위와 같이 바꿔낼 수 있습니다.
일단은 swap을 호출 할 때 swap(&zip1, &zip2) 처럼 인자 2개를 swap 함수에 넘겨서 호출해야 하는데 swap 쪽에서 받을 매개변수 자체가 어짜피 지역변수 취급이기 때문에 지역 변수가 저장되는 스택 메모리에 저장해서 넘겨야 합니다.
그렇기에 swap 함수에서 인자로 넘겨야할 zip1의 주소와 zip2의 주소를 스택 메모리에 push한 후 (스택구조이므로 push 순서는 반대로 넣어야 합니다. 역순으로 넣어야 꺼낼때 정방향이기 때문) call swap을 통해 swap 함수를 호출해줍니다.
그리고 j++ 에 해당하는 것 add 명령어가 실행됩니다.
* 현재 어셈블리 코드에서 zip1, zip2는 전역변수로 편의상 zip1과 zip2의 주소라고 생각
일단은 push 명령어를 통해 zip2, zip1이 push 되고 call swap 을 실행한 순간 call 명령어의 동작 원리에 따라 Return Address (다음에 실행할 명령어 주소 == EIP) 를 스택에 Push한 후 바로 swap 위치로 뛰어서 함수를 실행합니다.
3가지 값 모두가 call_swap() 의 스택 프레임에 저장되게 됩니다.
현재 call_swap()이 실행중이라 실행중인 스택 프레임에 대해 ESP가 스택의 TOP을, EBP가 스택의 BOTTOM을 가리키고 있는것도 주목해주세요.

이제 swap() 함수가 실행될 것인데 당연히 함수가 실행되면 그에 대한 스택 프레임이 잡히므로 swap() 에 대한 스택 프레임이 잡히고 swap 스택 프레임안에 swap 에서 사용하는 지역 변수 등을 저장하게 됩니다.
C언어 코드로 작성한 swap 함수를 어셈블리어로 바꾸면 오른쪽과 같은 형태가 됩니다.
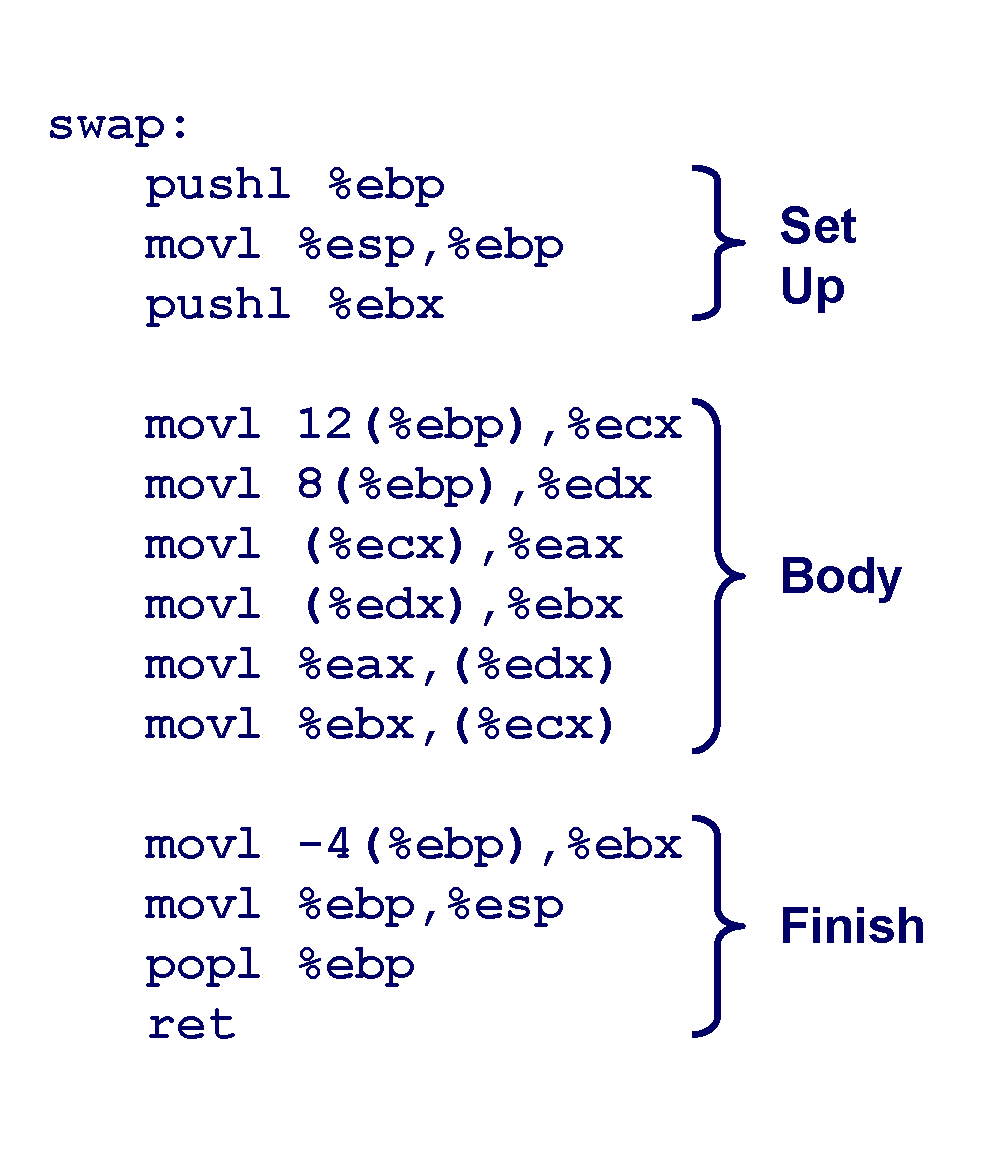
이 어셈블리 코드로 변환된 swap 함수 코드가 상당히 중요한 의미를 가지게 됩니다.
보시다 싶이 swap 함수의 코드를 Set Up, Body, Finish 로 나누어서 구분하고 있습니다.
우선 Set Up 부분의 경우 swap 스택 프레임을 설정하는 부분, Body는 실제 C-Code 가 수행되는 부분 (기능이 수행 되는 부분), Finish는 swap 함수를 끝마치고 나오는 부분입니다.
Set Up -> Body -> Finish를 순서대로 swap 함수가 호출될 때 어떤식으로 작동하는지 확인해봅니다.

아까 사진에서 확인했듯이 약간 연빨강(?) 색을 띄는게 call_swap의 스택 프레임입니다.
swap 함수로 들어와서 코드가 실행된 순간 swap 함수에 대한 스택 프레임이 노란색으로 만들어집니다.
swap 함수에서 제일 처음 하는게 우선 현재 ebp의 값을 스택 메모리에 push하는 일입니다.
이렇게 하면 원래 call_swap의 bottom을 가리키고 있던 ebp 값을 백업할 수 있습니다.
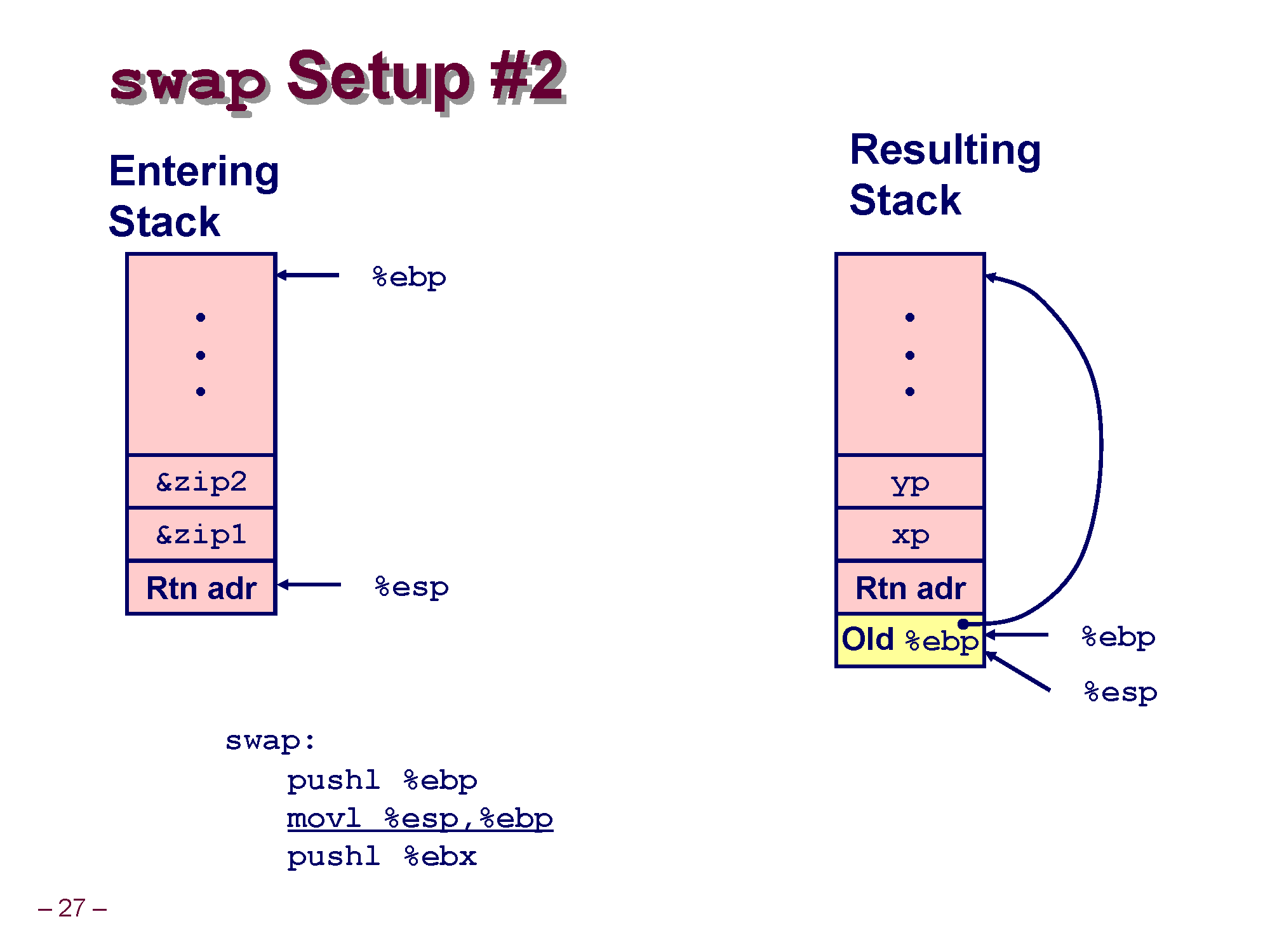
두번째로 esp 레지스터의 값을 ebp 레지스터로 옮깁니다.
앞에서 설명드렸듯이 ESP 레지스터랑 EBP레지스터는 현재 실행중인 스택 프레임의 Top과 Bottom을 가리켜야 하는데, 현재 swap 함수가 실행되고 있으니 ebp 레지스터랑 esp 레지스터가 swap 함수의 스택 프레임 위치를 잘 가리키고 있어야 겠죠 ㅋㅋ
물론 esp의 경우 push나 pop을 수행할때마다 자동적으로 증가 & 감소하지만 ebp 레지스터 값은 그렇지 않으니깐요.
mov 명령어를 통해 수동으로 조정해줘야 합니다.
어쨌던 간에 mov %esp, %ebp / 인텔 어셈블리어 포맷으로는 mov ebp, esp 를 하면 ebp 레지스터의 값이 esp 레지스터의 값이 되어 ebp 레지스터가 esp 레지스터랑 같은 위치를 가리키게 됩니다.
일단 데이터가 하나밖에 없으니깐 TOP이랑 Bottom이 똑같아야 해서 이렇게 하는게 맞겠죠?
결론적으로 esp와 ebp가 현재 실행중인 swap 함수의 프레임 위치를 가리킬 수 있도록 합니다.

그리고 3번째로 큰 의미는 없지만 현재 ebx 레지스터의 값을 swap의 스택 프레임으로 push 합니다.
아마 top과 bottom이 구분되지 않아서 좀 불편했나 봅니다. ebx 레지스터 값에 뭐가 들어있는진 모르겠는데 일단은 ebx 값을 push 해서 ebx 레지스터의 값도 백업해줍니다.
이러면 push 명령에 의해 esp 레지스터 값이 swap 스택 프레임에 들어가고 주소는 4만큼 감소하게 됩니다.
ebp 레지스터는 Base Register, 스택 메모리의 시작 위치를 가리키고 있는 특성상 움직이지 않습니다.

이제 swap 함수 입장에선 인자로 들어온 zip1과 zip2의 주소를 가져와서 값을 스와핑 해줘야 합니다.
그런데 현재 zip1과 zip2의 주소는 노란색 swap 의 프레임에 없고 아까 호출한쪽, 빨간색으로 되어있는 call_swap() 의 스택 프레임에 들어있습니다.
swap 함수의 입장에선 ebp나 esp 주소 값을 이용해서 call_swap 스택 프레임쪽의 zip1, zip2의 주소를 가져와야 하는데요.
알다 싶이 esp 레지스터는 항상 스택의 top을 가리키고 있고 push & pop 을 하면 가변적으로 변합니다.
그러니깐 조작전까지 스택의 시작을 가리키고 있고 변하지 않는 ebp 레지스터를 활용하면 좋을것 입니다.
zip1의 주소를 xp, zip2의 주소를 yp라고 하면 현재 xp, yp는 ebp 레지스터를 기준으로 -8, -12 라는 주소 위치에 존재합니다. 즉 swap 함수 스택 프레임에서 call_swap 함수 스택 프레임의 xp, yp 값을 가져오려면
[ebp - 8] 값과 [ebp - 12] 값을 메모리에서 가져오면 됩니다.
이 값을 참고해서 xp, yp 의 값을 어셈블리어로 자~알 바꿔줍니다.
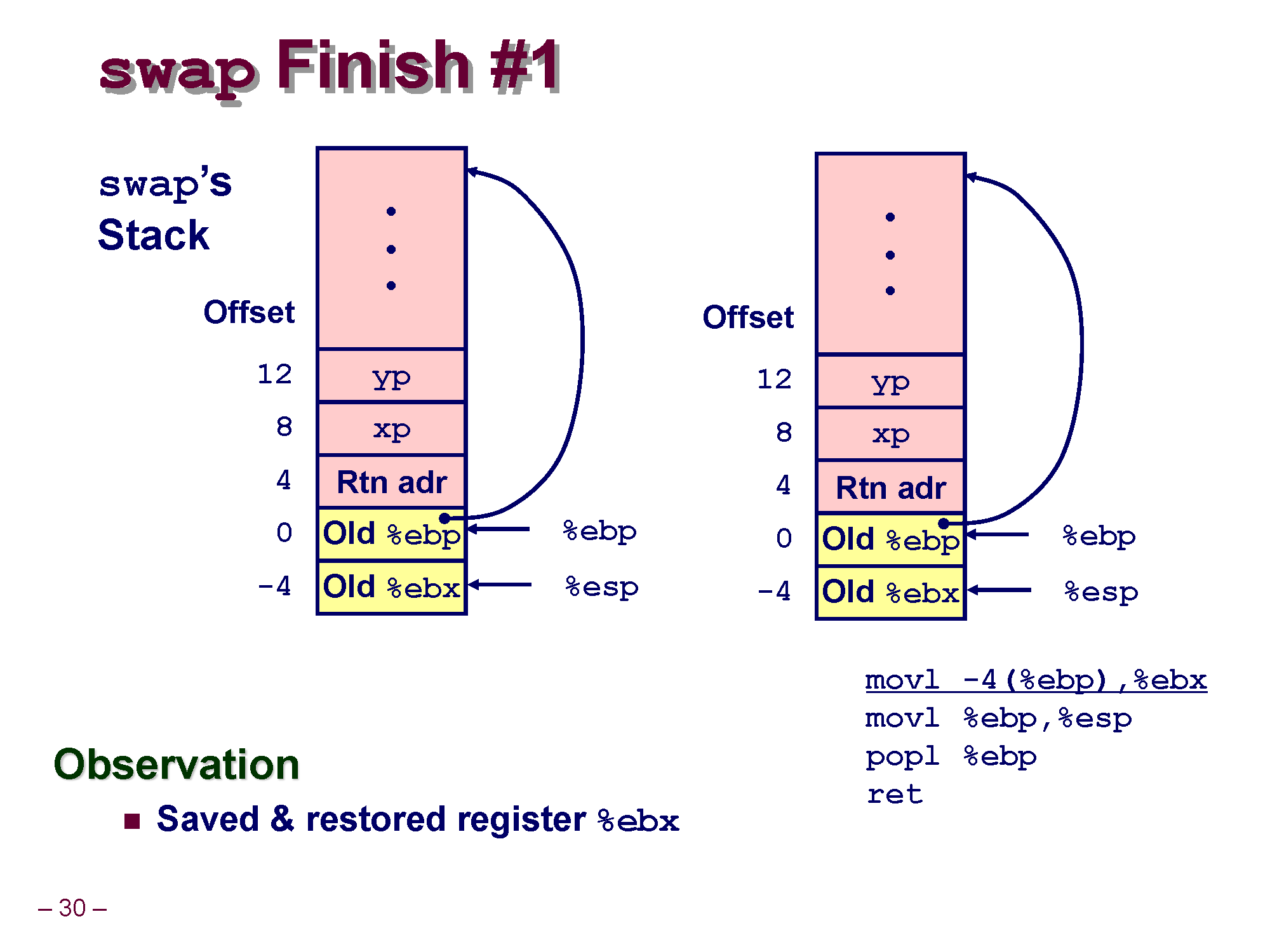
Body Code의 실행이 끝나서 xp, yp 위치의 값이 잘 swap 되었고 마지막으로 swap 함수의 수행이 끝났으니깐 swap 함수의 스택 프레임은 삭제하고 call_swap 스택 프레임 위치로 돌아가서 다시 함수를 실행시켜야 합니다.
우선 아까전에 백업한 ebx의 값을 원래 위치대로 되돌려 놔야 합니다.
역시 스택의 시작을 가리키는 ebp 레지스터를 이용해 [ebp - 4] 위치의 값이 ebp 레지스터 값이니깐
[ebp - 4] 값을 ebx 위치로 되돌려 놓습니다.

그리고 ebp 레지스터의 값을 esp 레지스터의 값으로 복사합니다.
이렇게 하면 esp 레지스터랑 ebp 레지스터가 같은 위치를 바라볼 수 있게 합니다.
esp 레지스터가 Top을 바라보게 하는 코드라고 보시면 됩니다.
요소가 1개라 Top Bottom이 똑같으니깐요 =ㅅ=

최종적으로 pop ebp를 수행해서, 마지막으로 남은 swap 스택 프레임 안에 들어있는 값을 빼내서 ebp에 저장합니다.
Old %ebp 라고 적혀있는 부분엔 사실 이전 call_swap의 EBP 레지스터 값이 들어가 있습니다.
지금 상황의 경우 swap의 함수 호출이 끝나서 swap의 스택 프레임을 삭제하고, 다시 call_swap 스택 프레임으로 복귀해서 실행하는 부분입니다.
이렇게 돌아오는걸 하려고 처음에 swap 함수 안에서 기존 EBP 레지스터 값을 백업한 것이죠.
이렇게 하면 원래 call_swap의 EBP 위치가 현재 EBP가 되어 call_swap 위치로 다시 옮겨가 call_swap 함수를 실행시킬 수 있습니다! 신기하죠?
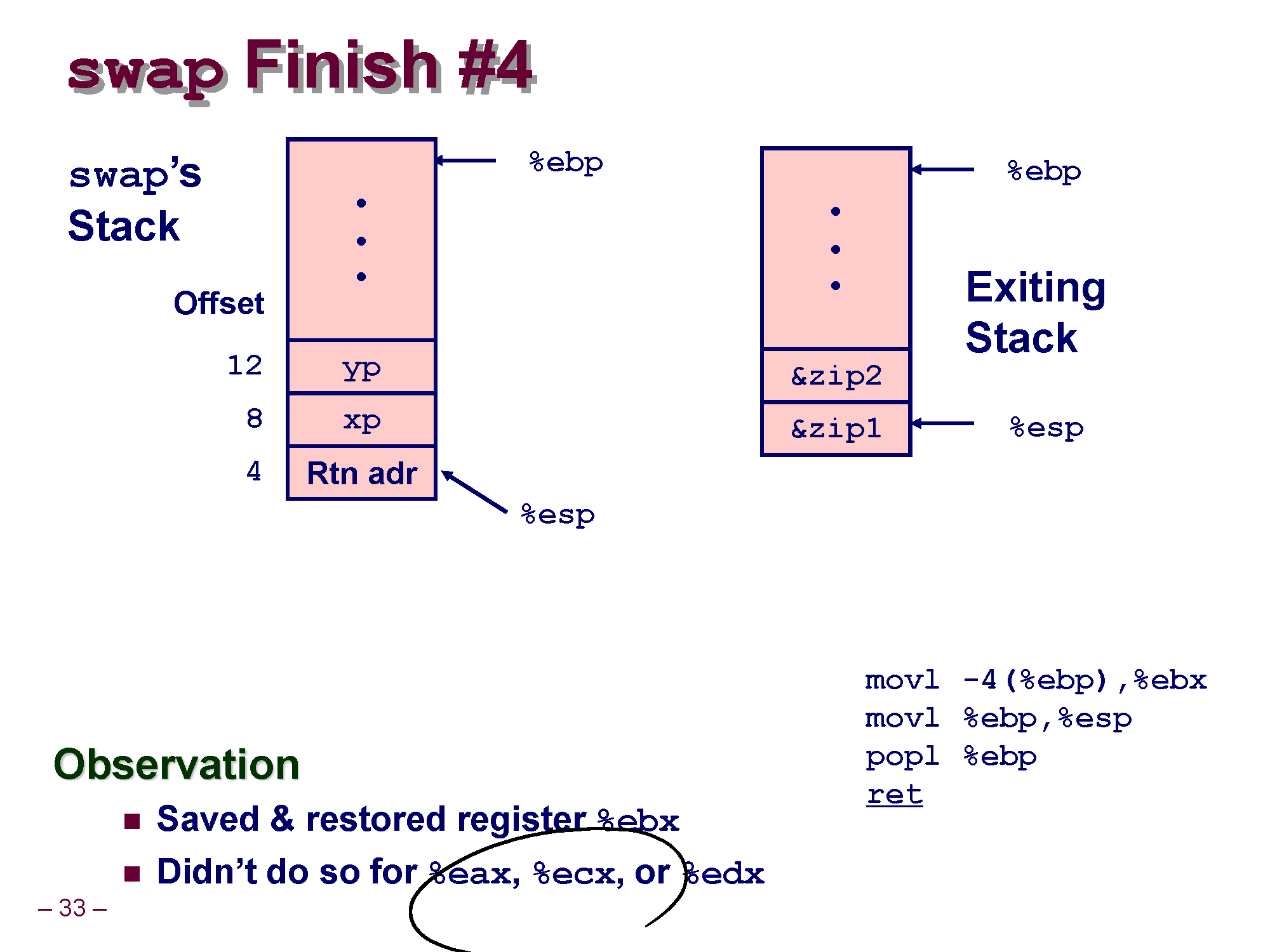
아직 안끝났습니다! swap 함수 안에서 최종적으로 ret를 실행하면 현재 스택 메모리 Top에서 값을 빼낸 다음 esp 레지스터 값을 4만큼 증가시키게 됩니다.
call_swap 이 호출될때 Return Address를 스택 메모리에 push했었잖아요? 이걸 ret을 실행시키면 pop + jmp가 수행되어 swap 에서 call_swap으로 복귀하여 바로 다음 코드가 실행될 수 있게 하는겁니다.
일단은 글로 쓰고 보니 설명이 굉장히 어렵게 된 거 같은데.. 저는 말로 설명 들어도 한번에 이해를 못했는데 지금 글쓰면서 어느정도 이해가 되네요 ㅎㅎ;;
어쨌던 간에 함수 호출의 원리가 이렇습니다..
일단은 더 적고 싶은 말도 많고 설명도 빈약합니다만 시간이 나면 더 추가로 글을 작성하도록 하겠습니다. 글 내용이 길어지니깐 티스토리 에디터 렉이 장난이 아니네요;; 그럼 다음에 뵙겠습니다.
출처
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=shackerz&logNo=220473532035
https://rond-o.tistory.com/304
https://eliez3r.github.io/post/2019/10/16/study-system.Stack-Frame.html
'CS > System' 카테고리의 다른 글
| [시스템 소프트웨어] 쓰레드(Thread)를 알아보자!! - 시스템의 핵심 (0) | 2023.05.08 |
|---|---|
| [시스템 소프트웨어] 어셈블리어 개요 / 어셈블리어(Assembly)란? (0) | 2022.12.26 |
| [Unix] 시스템 소프트웨어 개요 / 시스템 프로그래밍이란 무엇인가? (OS, System Call) (0) | 2022.11.16 |








