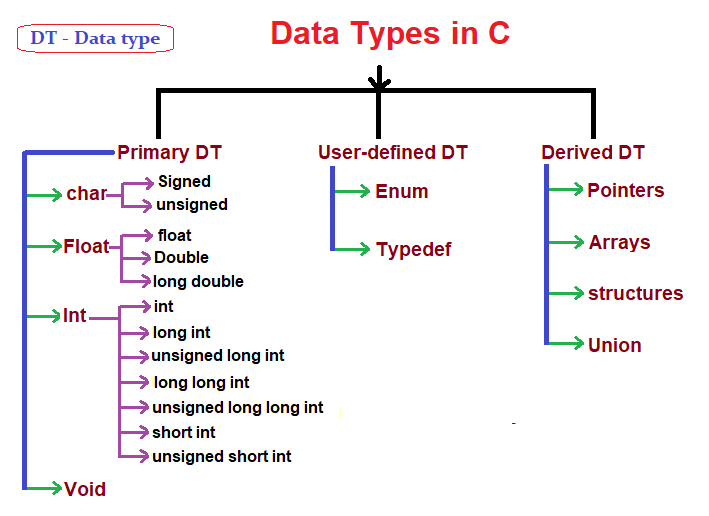
안녕하세요 파일입니다. 이전 강의에서 정수형은 int형, 실수형은 float형이라고 다룬 적이 있었죠?
자료형에 관한 표도 봤었구요. 그런데 자료형이 뭘까요?
앞에서 변수를 배웠습니다 그렇죠? 변수는 선언할 때 int a 처럼 앞에 데이터를 저장할 형식을 지정해줍니다.
이것이 자료형입니다. 자료형이란 변수의 저장하는 데이터의 형식입니다.
정수를 저장하고 싶다면 int, long, char 등을 사용하구요
실수를 저장하고 싶다면 float, double, long double 등을 사용합니다.
각 자료형에는 할당되는 메모리의 크기가 있습니다. 이것은 sizeof 함수를 이용해 구할 수 있습니다.
#include <stdio.h>
int main(void){
//정수형
char n1 = 5;
short n2 = 10;
int n3 = 30;
long n4 = 40;
//실수형
float n5 = 1.3;
double n6 = 1.4;
long double n7 = 1.5;
printf("------정수형------ \n");
printf("%d, %d \n", sizeof(n1), sizeof(char));
printf("%d, %d \n", sizeof(n2), sizeof(short));
printf("%d, %d \n", sizeof(n3), sizeof(int));
printf("%d, %d \n", sizeof(n4), sizeof(long));
printf("------실수형------ \n");
printf("%d, %d \n", sizeof(n5), sizeof(float));
printf("%d, %d \n", sizeof(n6), sizeof(double));
printf("%d, %d \n", sizeof(n7), sizeof(long double));
}
------정수형------
1, 1
2, 2
4, 4
4, 4
------실수형------
4, 4
8, 8
16, 16
--------------------------------
Process exited after 0.02011 seconds with return value 0
계속하려면 아무 키나 누르십시오 . . .
sizeof(변수)를 하면 변수의 메모리 크기가 나오고 sizeof(자료형)을 하면 자료형의 크기가 나옵니다.
출력 값을 보면 아시다시피 자료형과 변수의 메모리 크기는 같습니다.
저 출력 값은 바이트 값인데 int형은 4바이트의 크기로 출력을 한다는 것을 알 수 있습니다.
저 자료형의 크기는 컴퓨터가 몇 비트냐에 따라 다르게 나옵니다.
32비트 컴퓨터에서는 int 형이 4바이트(32비트)입니다.
그러면 64비트 컴퓨터에선 int형이 8바이트일까요? 그건 아닙니다.
64비트 운영체제에서는 int 가 32bit(4byte)로 고정되어 사용됩니다.
이유는 int형의 크기가 64비트 컴퓨터에서 8바이트일 이유가 없고.. 32bit 프로그램이 64bit로 옮겨가면서
모두 수정해야 할 상황이 생길 수 있기 때문이라고 합니다.
이에 관해선 인터넷에 정보들이 많으니 직접 찾아보시길 바랍니다.
정수형
자료형에 할당된 메모리 크기는 데이터를 표현할 수 있는 범위와 연관이 있습니다.
아래는 정수형 자료형의 표현 범위입니다.
| 정수형 | 크기 | 데이터 표현범위 |
| char | 1바이트 | -128 ~ +127 |
| short | 2바이트 | -32768 ~ + 32767 |
| int | 4바이트 | -2147483648 ~ + 2147483647 |
| long | 4바이트(32bit)/8바이트(64bit) | -2147483648 ~ + 2147483647 |
| long long | 16바이트 | -9223372036854775808 ~ +9223372036854775807 |
데이터의 표현 범위를 구할 때는 $-2^{n-1}(최소)$ ~ $2^{n-1} - 1(최대)$ 의 공식으로 구해집니다.
이 공식을 외울 필요는 없습니다. 데이터의 표현 범위를 구해주는 라이브러리가 있습니다 이름은 limits.h(절댓값)입니다.
당연하겠지만 데이터 표현 범위가 넓을 수록 표현할 수 있는 수가 큽니다.

파일을 찾아보면 데이터 표현범위가 매크로 상수 #define으로 정의되어 있습니다.
상수는 대문자로 하는 게 관례라고 상수 편에서 배웠는데 기억나시나요 ^^?
#include <stdio.h>
#include <limits.h>
int main(void){
printf("%d, %d \n", CHAR_MIN, CHAR_MAX); //Char 최대값 , 최소값
printf("%d, %d \n", SHRT_MIN, SHRT_MAX);
printf("%d, %d \n", INT_MIN, INT_MAX);
printf("%ld, %ld \n", LONG_MIN, LONG_MAX);
printf("%lld, %lld \n", LONG_LONG_MIN, LONG_LONG_MAX);
printf("%lld, %lld \n", LLONG_MIN, LLONG_MAX);
}
-128, 127
-32768, 32767
-2147483648, 2147483647
-2147483648, 2147483647
-9223372036854775808, 9223372036854775807
-9223372036854775808, 9223372036854775807
--------------------------------
Process exited after 0.01935 seconds with return value 0
계속하려면 아무 키나 누르십시오 . . .전처리기에서 limits.h 를 임포트 한 뒤 자료형 이름_MAX 또는 자료형 이름_MIN를 하면 최대 최소를 구할 수 있습니다.
직접 출력하면서 값을 확인해보세요 ^^
long을 출력할 땐 %ld, long long 을 출력할땐 % lld를 사용합니다.
LLONG과 LONG_LONG 은 같은 의미입니다.
특이한 점은 short를 출력할 때 SHORT 가 아닌 SHRT를 사용한다는 점이네요.
#include <stdio.h>
int main(){
printf("%d \n", 2147483647);
printf("%d \n", 2147483647+1); //오버플로우 발생
printf("%u \n", 2147483647 * 2); //표현가능
printf("%u \n", -1 * 2147483647 * 2); //표현불가
}
2147483647
-2147483648
4294967294
2
--------------------------------
Process exited after 0.0227 seconds with return value 3
계속하려면 아무 키나 누르십시오 . . .저번 printf 편에서 사용했던 서식 문자 % u를 사용했던 예제인데요.
% u를 사용하면 정수 값의 2배를 출력할 수 있는 대신 음수 값을 출력할 수 없다고 했습니다
이 u는 Unsinged의 약자입니다. 뜻하자면 '부호가 없는'입니다.
우리가 대게 사용하는 자료형 int를 생각해봅시다.
int 앞엔 사실 singed 가 생략돼서 사용하는 건데요, singed는 부호가 있다는 의미로 음수, 0, 양수를
모두 표현할 수 있습니다. 하지만 unsinged 키워드가 붙게 되면 음수 부분의 출력 범위가 양수 부분으로 넘어가게 되고
양수 출력 범위는 2배가 되며 음수는 표현할 수 없게 됩니다. 위 예제를 보면% d 2배를 % u로
출력할 수 있지만 음수 값 출력이 안되는 걸 알 수 있습니다.
즉 키워드 unsinged 가 붙으면 0, 양수(기존 출력 범위의 2배)를 출력하게 됩니다.
limits.h 를 이용해 unsinged 값들의 데이터 표현 범위도 볼 수 있습니다.
#include <stdio.h>
#include <limits.h>
int main(void){
printf("%u \n", UINT_MAX);
printf("%lu \n", ULONG_MAX);
printf("%llu", ULLONG_MAX);
}
4294967295
4294967295
18446744073709551615
--------------------------------
Process exited after 0.01927 seconds with return value 0
계속하려면 아무 키나 누르십시오 . . .직접 출력 값들을 확인해보세요~ 어때요 양수 표현 범위가 2배가 되었죠 ^^?
ULONG 출력 시 %lu, ULONG_LONG 출력시 % llu를 사용합니다.
그냥 % d 가 % u로 바뀐 게 전부예요.
MIN 값을 구하려면 오류가 날건대 이건 의미가 없기 때문입니다. 음수는 표현이 안되니 최솟값은 어차피 0이겠죠..
크기가 작은 자료형은 최적화에 도움이 될까?
우리가 물건을 담을 때 사과 하나를 담는다면 봉지 하나만 있으면 됩니다. 큰 카트는 필요 없죠
그러면 컴퓨터에서 1이라는 정수를 담을 때도 int형이 아닌 메모리 크기가 더 작은 char 값에 담는 게 더 효율적일까요?
그렇지는 않습니다. 컴퓨터에서는 정수형 중에서도 int형을 가장 빠르게 처리하기 때문입니다.
컴퓨터가 한 번에 64,32 비트씩 연산하는데 char 은 1바이트 차지하고 int형은 4바이트(32비트) 차지하므로
char로 변수를 만들게 되면
char로 쪼개는 과정이 한 번 더 일어납니다. 그래서 조금 더 시간이 걸리게 됩니다. 물론 이것을 체감하긴 어렵겠지만;;
최적화를 위한 자료형의 크기 고려보다는 각 자료형의 호환성을 잘 고려하면서 프로그래밍하는 것이 좋습니다.
char a = 10; 일 때도 10이 자동으로 int형으로 변환된 뒤 char형태로 변환되어 대입됩니다.
오버플로우와 언더플로우
각 자료형 데이터 표현 범위의 최댓값보다 큰 값을 저장하면 오버플로우가 발생하고 최솟값보다 작은 값을 저장하면
언더플로우가 발생하게 됩니다.

이때 오버플로우가 발생하면 최솟값부터 다시 새고, 언더플로우가 발생하게 되면 최댓값부터 다시 샙니다.
즉 수가 순환하게 되는데 위 사진을 참고해주세요.
#include <stdio.h>
#include <limits.h>
int main(void){
char a = 130; //char 값의 최대표현범위는 127
char b = -129; //char 값의 최소표현범위는 -128
//a는 최대값의 3만큼 초과
//b는 최소값보다 1작음
printf("%d %d", a,b);
}
'프로그래밍 강좌 > C' 카테고리의 다른 글
| [C언어 강좌] #8 반복문(For, While, Do~While, 무한루프, 중첩) (13) | 2019.12.23 |
|---|---|
| [C언어 강좌] #7-2 자료형(Data Type) (0) | 2019.11.24 |
| [C언어 강좌] #6-2 연산자(Operator) (5) | 2019.11.15 |
| [C언어 강좌] #6-1 연산자(Operator) (4) | 2019.11.14 |
| [C언어 강좌] #5-2 [2진수 변환, 1의보수, 2의보수 원리 설명] (0) | 2019.11.12 |








