import requests
from bs4 import BeautifulSoup
import time
from os.path import getsize
def image_download(BASE_URL):
# 헤더 설정 (필요한 대부분의 정보 제공 -> Bot Block 회피)
headers = {
"Connection" : "keep-alive",
"Cache-Control" : "max-age=0",
"sec-ch-ua-mobile" : "?0",
"DNT" : "1",
"Upgrade-Insecure-Requests" : "1",
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Sec-Fetch-Site" : "none",
"Sec-Fetch-Mode" : "navigate",
"Sec-Fetch-User" : "?1",
"Sec-Fetch-Dest" : "document",
"Accept-Encoding" : "gzip, deflate, br",
"Accept-Language" : "ko-KR,ko;q=0.9"
}
res = requests.get(BASE_URL, headers=headers)
html = res.text
soup = BeautifulSoup(html, 'html.parser')
# 아래 이미지 다운로드 받는 곳에서 시작
image_download_contents = soup.select("div.appending_file_box ul li")
for li in image_download_contents:
img_tag = li.find('a', href=True)
img_url = img_tag['href']
file_ext = img_url.split('.')[-1]
#저장될 파일명
savename = img_url.split("no=")[2]
headers['Referer'] = BASE_URL
response = requests.get(img_url, headers=headers)
path = f"Image/{savename}"
file_size = len(response.content)
if os.path.isfile(path): #이름이 똑같은 파일이 있으면
if getsize(path) != file_size: #받을 파일과 기존파일의 크기가 다를경우 (다른 파일일경우)
print("이름은 겹치는 다른파일입니다. 다운로드 합니다.")
file = open(path + "[1]", "wb") #경로 끝에 [1] 을 추가해 받는다.
file.write(response.content)
file.close()
else:
print("동일한 파일이 존재합니다. PASS")
else:
file = open(path , "wb")
file.write(response.content)
file.close()
def image_check(text):
text = str(text)
if "icon_pic" in text:
return True
else:
return False
while True:
BASE_URL = "https://gall.dcinside.com/board/lists?id=baseball_new10"
# 헤더 설정 (필요한 대부분의 정보 제공 -> Bot Block 회피)
headers = {
"Connection" : "keep-alive",
"Cache-Control" : "max-age=0",
"sec-ch-ua-mobile" : "?0",
"DNT" : "1",
"Upgrade-Insecure-Requests" : "1",
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Sec-Fetch-Site" : "none",
"Sec-Fetch-Mode" : "navigate",
"Sec-Fetch-User" : "?1",
"Sec-Fetch-Dest" : "document",
"Accept-Encoding" : "gzip, deflate, br",
"Accept-Language" : "ko-KR,ko;q=0.9"
}
res = requests.get(BASE_URL, headers=headers)
if res.status_code == 200:
html = res.text
soup = BeautifulSoup(html, 'html.parser')
#print(soup)
doc = soup.select("td.gall_tit > a:nth-child(1)")
for i in range(4,len(doc)): #공지사항 거르고 시작 (인덱스 뒤부터)
link = "https://gall.dcinside.com" + doc[i].get("href") #글 링크
title = doc[i].text.strip() # 제목
image_insert = image_check(doc[i]) #이미지 포함여부
print(link, title, image_insert)
if(image_insert == True): #이미지 포함시
image_download(link) #이미지 다운로드하기
break #바로 break해서 첫글만 가져옴
time.sleep(0.5)무한반복하여 0.5초마다 최상단 최신글 받아오고 이미지가 포함된 글이면 이미지를 다운로드하는 예제입니다.
끝부분 break를 제거해주면 앞에 노출된 페이지 글을 전부 크롤링 합니다.
소스 설명
# 헤더 설정 (필요한 대부분의 정보 제공 -> Bot Block 회피)
headers = {
"Connection" : "keep-alive",
"Cache-Control" : "max-age=0",
"sec-ch-ua-mobile" : "?0",
"DNT" : "1",
"Upgrade-Insecure-Requests" : "1",
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Sec-Fetch-Site" : "none",
"Sec-Fetch-Mode" : "navigate",
"Sec-Fetch-User" : "?1",
"Sec-Fetch-Dest" : "document",
"Accept-Encoding" : "gzip, deflate, br",
"Accept-Language" : "ko-KR,ko;q=0.9"
}
디시인사이드의 경우 일반적인 웹 파싱 방법으로 접근하면 되나
User-Agent 하나만 넘겨선 봇으로 인식해 연결을 막아버립니다.
예전엔 됬던거 같은데 요즘은 검사가 더 추가 된듯 합니다. 이걸 해결하는게 관건인데 해결방법은 그렇게 어렵지 않습니다. 일반적으로 크롬에서 디시인사이드 요청시 보내는 헤더를 거의 전부 똑같이 넘겨버리면 됩니다.
image_download_contents = soup.select("div.appending_file_box ul li")
for li in image_download_contents:
img_tag = li.find('a', href=True)
img_url = img_tag['href']
file_ext = img_url.split('.')[-1]
#저장될 파일명
savename = img_url.split("no=")[2]
headers['Referer'] = BASE_URL또한 이미지 다운로드시 왔던 Referer을 넘겨야 정상적으로 이미지 서버에서 응답을 한다고 합니다.
Referer도 중간에 다운로드할때 Headers 목록에 추가해서 넘겨줍니다.
프로그램 사용 예시
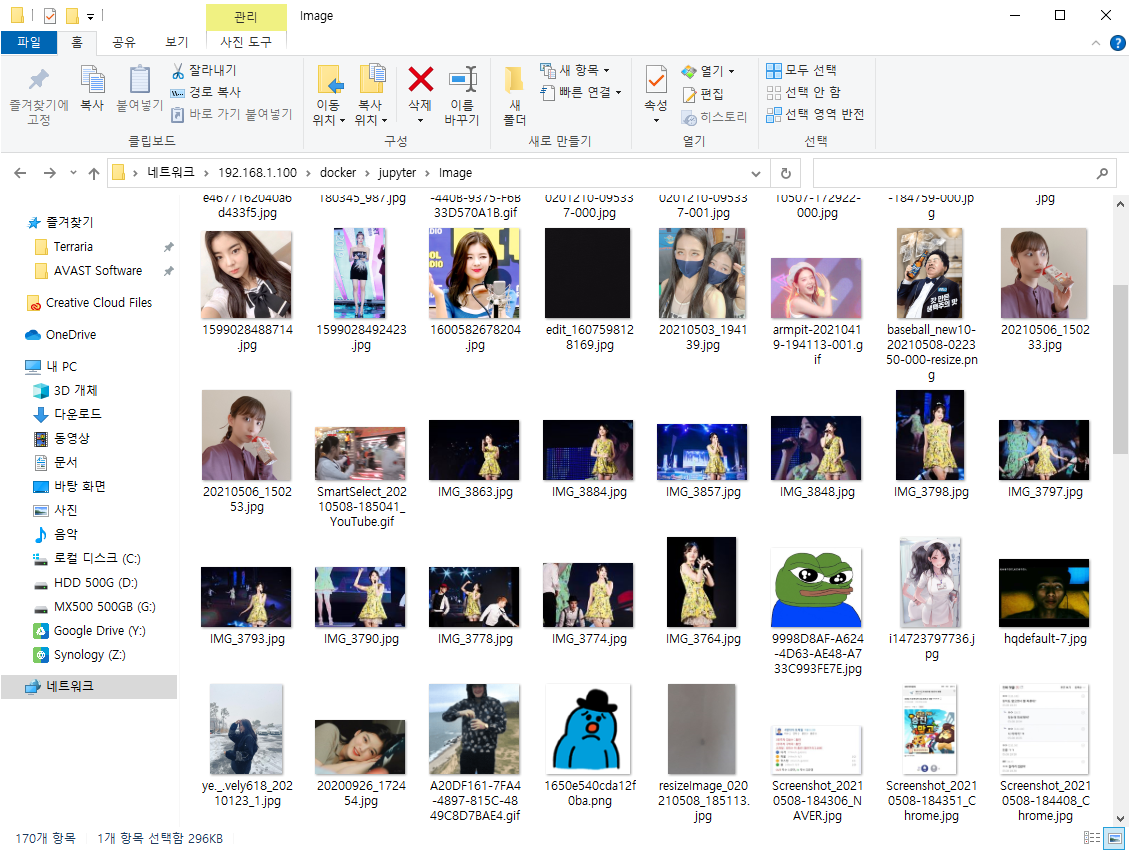
한 1시간정도 돌려봤는데 이미지 자체가 압축되어있어서 짜잘한것들 뿐이지만 금방 1gb를 찍으려 하더군요.
NAS에서 돌려서 용량걱정은 거의 없었지만 이미지 서버들이 얼마나 큰 용량을 가지고 있을지 확인되는 부분이였습니다 ㅎㄷㄷ
그리고 새벽에 돌려보면 세상의 온갖 흉물스런 사진이 다 저장됩니다..
할카X라던가...
추가로 봐볼만한 것
디시인사이드 이미지 서버 문제점
https://velog.io/@mowinckel/%EB%94%94%EC%8B%9C%EC%9D%B8%EC%82%AC%EC%9D%B4%EB%93%9C%EC%9D%98-%EB%AC%B8%EC%A0%9C%EC%A0%90
'프로그래밍 > Python' 카테고리의 다른 글
| [Python] 이미지 URL 주소에서 확장자 추출하기 (0) | 2021.08.06 |
|---|---|
| [Python] 문제 풀이 코드 저장용 (0) | 2021.05.08 |
| [Python] LSTM 미래 주가 분석 참고글 (0) | 2021.02.04 |
| JupyterLab에서 사용자 지정 단축키 Keyboard ShortCuts 설정하기 (0) | 2020.12.13 |
| [Python] 폴더 특수문자 제거 및 HTML 태그 제거 함수 (0) | 2020.11.13 |







