파이썬에서 엑셀 파일을 불러오기 위해 OpenPyxl 를 써봤으나 처리 속도가 너무 느렸습니다.
대안을 찾아보다가 pandas 가 괜찮은 성능을 보여줘서 엑셀파일을 읽는 간단한 예제를 남겨봅니다.
pip install pandas우선 엑셀파일을 읽어오기 위해선 pandas 라이브러리가 필요합니다.
다음 명령어를 입력하여 설치해줍니다.
import pandas as pd
try:
#dtype=str -> 문자열 취급 -> 010 표시
df = pd.read_excel('example.xlsx', sheet_name = 'data', dtype=str)
for i in df.index: #엑셀의 인덱스 수만큼 반복한다.
name = df.loc[i, '이름'] #현재 인덱스의 이름을 가져온다
phone_num = df.loc[i, '전화번호'] #전화번호 가져오기
address = df.loc[i, '주소'] #주소 가져오기
print('{} {} {}'.format(name, phone_num, address))
except Exception as e:
print('Error : ', str(e))
>>>
홍길동 010-1234-5678 서울특별시 OO구 OO동 123-123
김철수 010-5678-9123 서울특별시 OO구 OO동 456-456
김미애 010-6666-7777 서울특별시 OO구 OO동 789-789해당 예제는 엑셀파일의 이름, 전화번호, 주소를 for문을 통해 불러오는 예제입니다.
반복작업시 유용합니다.
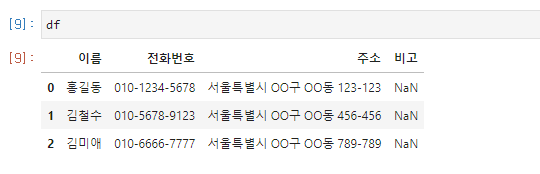
Jupyter Notebook을 이용해 df를 출력하면 다음과 같이 한번에 읽을 수도 있습니다.
'프로그래밍 > Python' 카테고리의 다른 글
| JupyterLab에서 사용자 지정 단축키 Keyboard ShortCuts 설정하기 (0) | 2020.12.13 |
|---|---|
| [Python] 폴더 특수문자 제거 및 HTML 태그 제거 함수 (0) | 2020.11.13 |
| [Python] PushBullet으로 SMS 전송하기 (1) | 2020.08.19 |
| [Python] Blynklib 로컬 서버 연결하기 (0) | 2020.03.15 |
| [Python] Mnist 데이터를 이용한 인공신경망 손글씨 인식 (0) | 2020.01.16 |









